![]()
English
社会・産業のデジタル変革

Why Open Dataspaces: 設計思想とアーキテクチャパラダイム(2026年4月1日)
公開日:2026年4月1日
デジタルアーキテクチャ・デザインセンター
独立行政法人情報処理推進機構デジタルアーキテクチャ・デザインセンターは、国や組織ごとの多様性を尊重する、オープンでスケーラブルな分散データマネジメントの技術コンセプトであるOpen Data Spacesの設計思想/アーキテクチャパラダイムの解説文書「Why Open Dataspaces: 設計思想とアーキテクチャパラダイム」を公開しました。
1. 目的
本書は、国や組織ごとの多様性を尊重する、オープンでスケーラブルな分散データマネジメントの技術コンセプトである「Open Data Spaces(ODS)」の設計思想、そしてその中核となるアーキテクチャパラダイムを提示するものです。なお、本書で利用する一般名称としての「Open Dataspaces」は、米国のデータスペースに関する原著論文(Franklin et al., 2005; Halevy et al., 2006)及びデータメッシュ(Dehghani, 2019; Dehghani 2022)を中核として、民間企業・団体と連携した研究開発・商用水準での検証を経ながら設計された新世代の分散データマネジメント技術及びそれを構成する概念を指します。
2. 背景: Agentic AI時代の到来とダークデータの可能性
2026年は、多くのテクノロジー市場関係者にとって「データ枯渇元年」と呼べる転換点です。
Epoch AI(2024)の推計によれば、主要LLMがこのままの速度で学習を進めた場合、特に高品質データが2026年から2032年の間に枯渇する可能性が示されています(図1)。
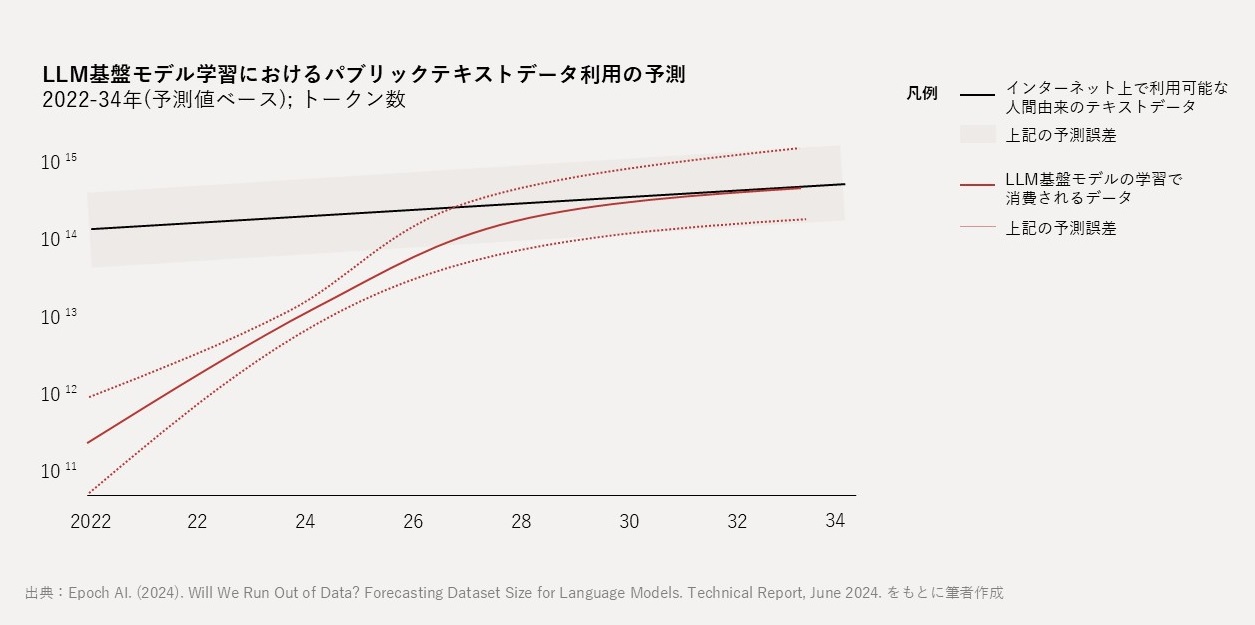
また、NEDO(2025)によれば、世界で創出されるリアルデータのうち、複製データを除去した有効量 約17.5ZBのうち約16ZBがインターネット非公開の「ダークデータ(Dark Data)」として企業内に留まっていると推定されています(図2)。

このダークデータは、潜在的な学習や推論の資源としての価値を持つものの、そのままでは利用できないケースが多くあります。ドメインオーナーがデータにコンテクストを与え、それを「プロダクト(商品)」として提供し、その利用を制御することが、企業価値の向上につながります。
3. 本書のエグゼクティブ・サマリー
集約から分散へ: データマネジメントのパラダイム変遷
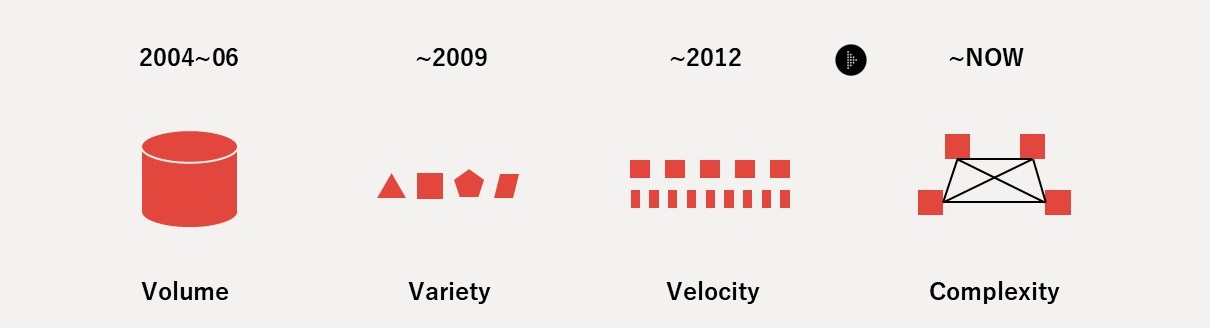
21世紀のデータマネジメントは、3Vs(Volume・Variety・Velocity)の課題を経て、現在は「複雑性(Complexity)」の問題に直面しています。このComplexityは、技術的な側面のみならず、産業・ビジネスの側面、社会的・組織的な側面、法制度・契約的な側面を含む多面的なものです(図3)。
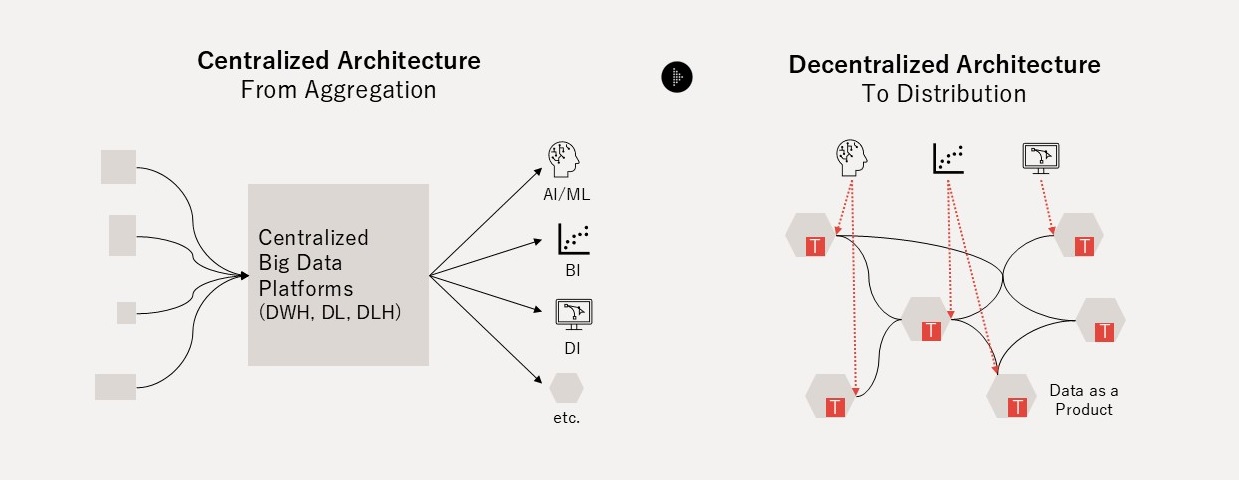
伝統的な「Push and Ingest」パラダイムは、組織内外のあらゆるデータを一箇所に集約するという「集約(Aggregation)」中心の発想から脱却できていません。ドメインが多岐にわたり、データソースも利用者も多様な組織においては、データの増加により技術的な複雑性が増し、利用コストも増大します。こうしたComplexityの時代には、所在が散逸し、組織の中で分断され、異なる構造や意味で存在するダークデータを適切なオペレーションコストでマネジメントするための解決策が必要です。この問題意識から登場した「Serving and Pull」型の分散アプローチがデータメッシュ(data mesh)であり、それを組織・国境横断へと発展させたものがOpen Dataspacesです。
データメッシュからOpen Dataspacesへ
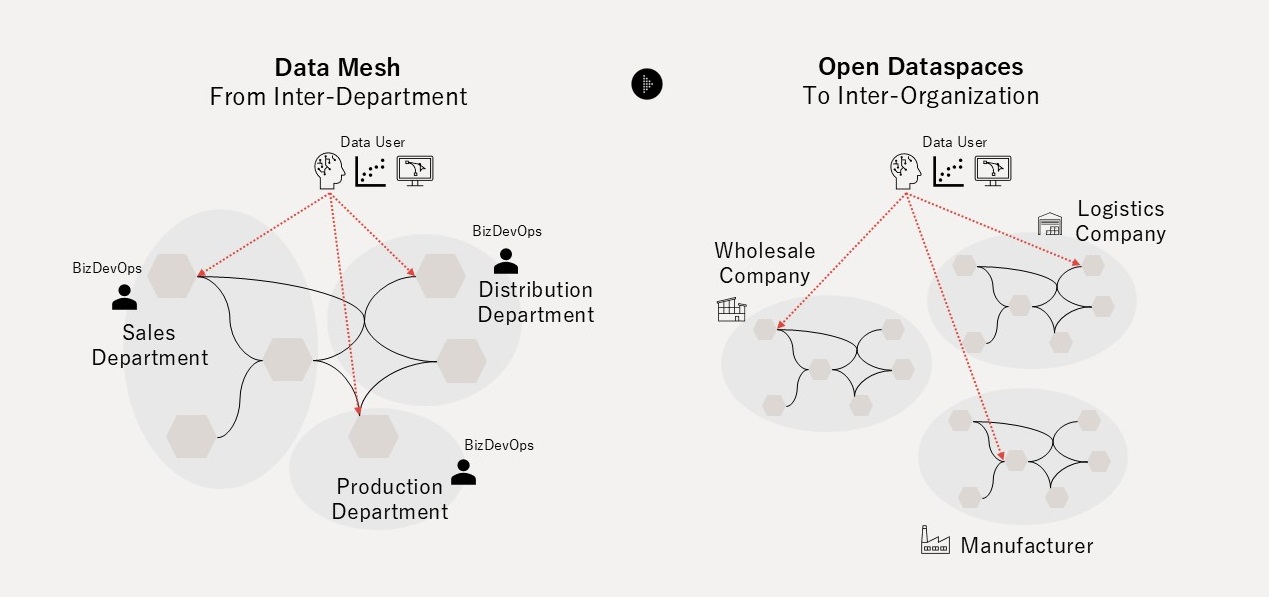
Zhamak Dehghani氏により考案されたデータメッシュは、「データの責任を、中央のデータ基盤から業務ドメインへと戻した」点で重要な転換点でした。データメッシュは、データを生み出すドメインオーナー自身(例: 広報部門、HR部門、商品開発部門 等)が、データを単なるオペレーションの副産物ではなく、明示的に設計・提供される「プロダクト(商品)」として扱うことで、中央集権的な調整や事前統合に依存せずとも、データ活用を組織内でスケールしうるものとしました(図4)。
しかし、データメッシュは「組織内」での部門間連携を暗黙の前提として提唱され、組織境界を越えた場合に顕在化するGovernance Complexityの問題には十分に答えきれていません。Open Dataspacesは、Classical Dataspaces(Franklin et al., 2005)の理念とデータメッシュのパラダイムを引き継いだ補完的なアーキテクチャパラダイムです。「(1)データの所在(Where to get)」「(2)データの意味(What to mean)」「(3)データの制御(Who and How to use)」という3つのGovernance Complexityの問題を解決することで、組織や国境を横断した分散データマネジメントを可能にします(図5)。
アーキテクチャの最小単位: Double-Product Quanta Model(DPQM)
Architectural Quanta(AQ)とは、分散データマネジメントにおけるアーキテクチャの最小の構成単位です。
Open Dataspacesでは、データメッシュのAQであるData Productの相互運用性の問題を解決するため、Data Productと表裏一体の関係性である「Ontology Product」という概念を新たに導入し、Data ProductとOntology Productを併せて構成単位のAQとしています。このAQのパラダイムをDouble-Product Quanta Model(DPQM)と呼称します(図6)。
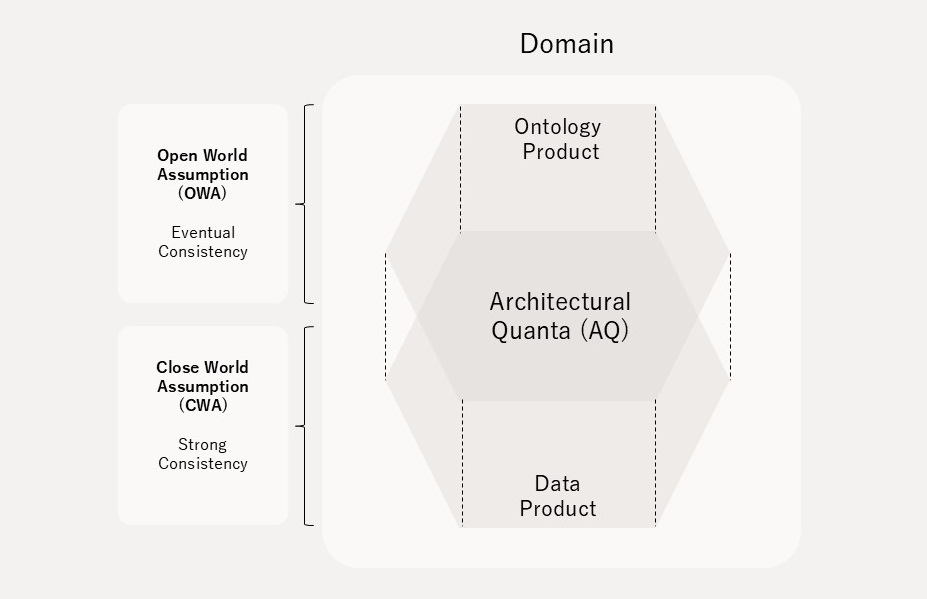
Open Dataspacesでは、Ontology Productで「(真と)判断できないことは、偽ではないとみなす」という開世界仮説(OWA: Open World Assumption)を前提としつつ、Data Productで閉世界仮説(CWA: Closed World Assumption)を選択的に導入するという二層構造を取っています。この設計が、データ提供者と利用者の期待値に存在するトレードオフを埋めます。Open Dataspacesは、先にインスタンス(データ)があり、そこに意味を後から付与する「スキーマフレキシブル(Schema Flexible)」という技術指針を採用しています。これは、Edgar Coddの関係モデルが前提とする集合論の束縛からの解放を意味します。
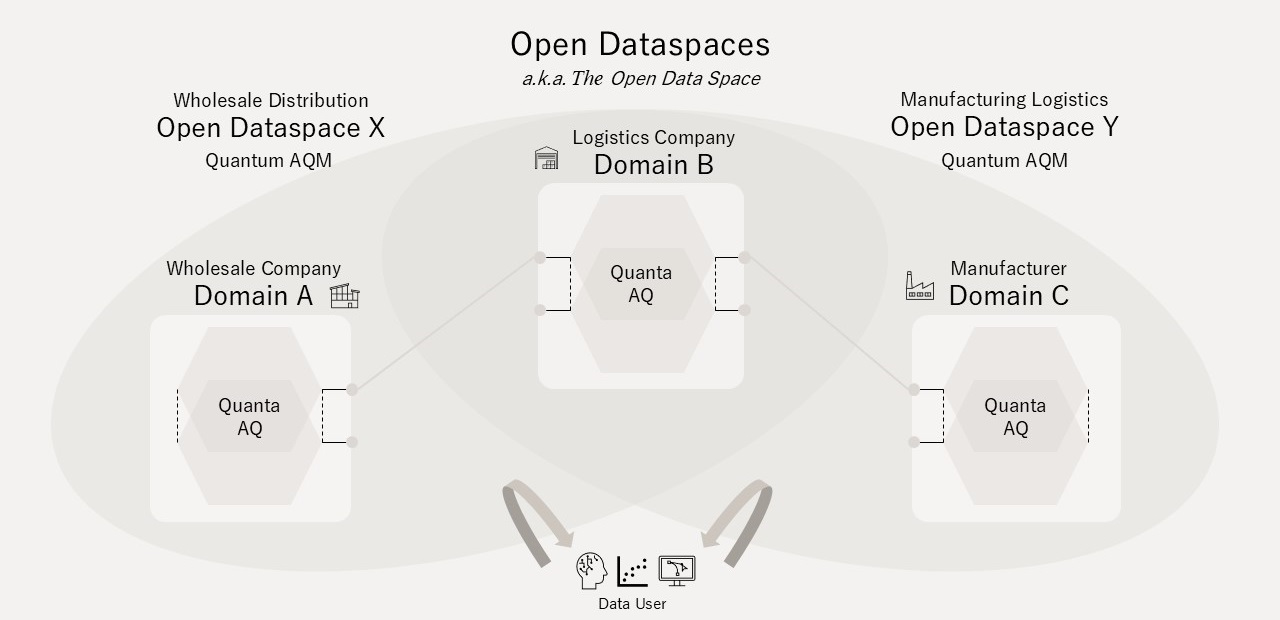
Open Dataspacesの構成
「(An)Open Dataspace」はDPQMの構成単位(AQ)が複数包含されることによって構成されるArchitectural Quantum(AQM)です。例えば、卸売業企業の物品ドメインAQと物流企業の倉庫ドメインAQによりWholesale Distribution Dataspace(AQM)が、同様に製造企業の生産ドメインAQとの組み合わせによりManufacturing Logistics Dataspace(AQM)が構成されます。
Open Dataspaceは動的・多元的に構成され、例えば、製造企業と卸売業企業が需給調整最適化のためのOpen Dataspaceを構成する場合、それぞれのAQを要素とします。このような多元的・重層的な集合関係を含むOpen Dataspaceの総体を「Open Dataspaces」または「The Open Dataspace」で呼称します(図7)。
アーキテクチャの3本の柱(DAD・OSI・IUC)
Open Dataspacesが提示するパラダイムの最大の特長は、データの組織・国境横断とAgentic AIの存在を前提として、大きな3つの柱を持つ分散型アーキテクチャにより、透過的なSingle Source of Truth(SSOT)と、データ提供者に相当するドメインオーナーに対する価値還元のメカニズムを実現することです(図8)。
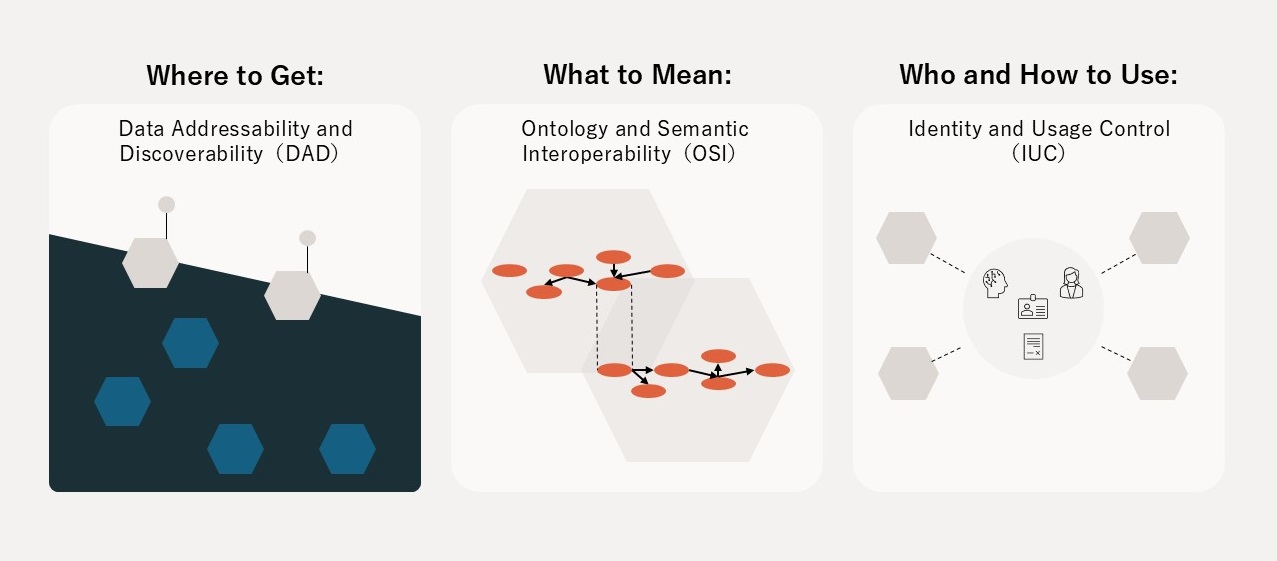
- 1. Ontology and Semantic Interoperability(OSI)
-
Open Dataspacesは、「データモデル(Data Model)」から「情報モデル(Information Model)」を明確に分離するDPQMを採用しています。情報モデルをデータモデルから分離することで、実運用で避けられない意味の進化を、データ構造の破壊ではなく、再解釈として扱うことが可能となります。さらに、LLMによるOntological Gapの改善を取り込んだ「Dynamic Ontology」により、Open Dataspacesは Agentic AIネイティブ時代のアーキテクチャとして「推測(Guess)から知識(Knowledge)」へのパラダイムシフトを促します。
- 2. Data Addressability & Discoverability(DAD)
-
Addressability を欠いたデータは、存在していないのと同義です。Open Dataspacesは、ドメイン外部に「Ontology Endpoint」と「Data Endpoint」という2つの独立したインターフェースを公開し、IRI(International Resource Identifier)により、ドメインごとに異なる内部識別子を温存したまま、グローバルに一意な存在証明を提供します。データ利用者が実体のデータソースに到達するには、任意キーワードに対してBest Effort Resultを返す「Ontology Query(第一段階)」とデータソースへの実アクセスを行う「Data Query(第二段階)」という2段階のクエリプロセスを経ます。データカタログは硬直的な静的リポジトリではなく、クエリ依存で都度生成される動的なビューワーであり、このAddressabilityとDiscoverabilityの組み合わせがDADを構成します。
- 3. Identity and Usage Control(IUC)
-
Open Dataspacesでは、信頼を前提ではなく設計対象として扱う「Trust by Design」を指針としています。アイデンティティを「実在性の検証(Identity Proofing)」「認証(Authentication)」「認可(Authorization)」の3要素に分解し、それぞれに異なる責務を与えています。さらに、「利用制御(Usage Control)」はアクセス制御を拡張した権利・義務的な概念であり、データ提供者と利用者の間にある権利義務・価格決定権の非対称性を補正するために、アーキテクチャレベルで導入しています。利用制御の手段を単一で硬直的な技術プロトコルで縛ることは市場導入のボトルネックになるため、Open Dataspacesは法域・制度的均質性を前提としない多様な方式を許容しています。
設計指針とサービスモデル
Open Dataspacesは、3つの柱を実現するための設計指針として、(1)ベンダーロックインの回避、(2)制度的ロックインの回避、(3)プロダクトライクでサービス志向の設計を根幹に置いています。プロトコルは疎結合に構成され、後方互換性を設計段階でビルトインしています。
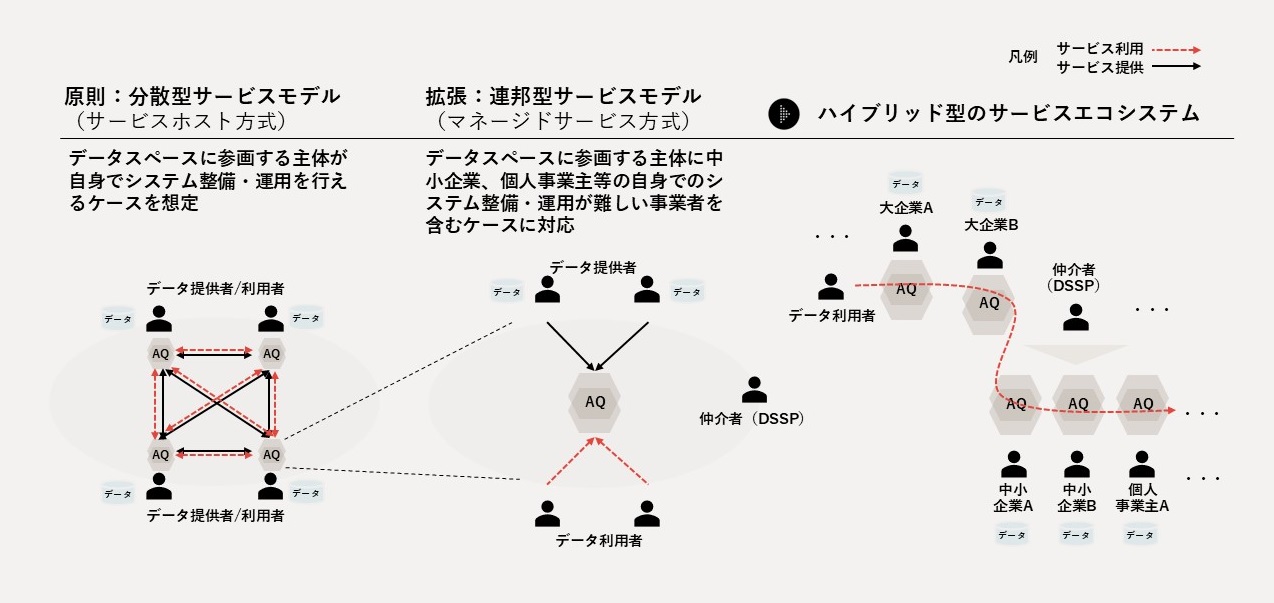
サービスモデルとして、(1)ドメインオーナー自身がSelf-Serve Data Platformを構築する「分散型サービスモデル」と、(2)DPQMを構成する基本的なソフトウェアスタックをマネージドサービス事業者(「Dataspace Service Provider(DSSP)」)に代理で提供してもらう「連邦型サービスモデル」の混成である「Hybrid Service Model(HSM)」を想定します(図9)。HSMにより、大企業から中小企業まで幅広い主体のOpen Dataspacesへの参加が可能になります。
4. 本書のダウンロード

本書は、以下リンクからダウンロードが可能です。
発行者
独立行政法人情報処理推進機構デジタルアーキテクチャ・デザインセンター
著者・編集者
津田 通隆 / Michitaka TSUDA:
Open Data Spaces Chief Architect(最高設計責任者)
コピーライト
独立行政法人情報処理推進機構
お問い合わせ先
本件に関するお問い合わせは以下の連絡先へお寄せください。
IPA デジタルアーキテクチャ・デザインセンター
-
E-mail
更新履歴
-
2026年4月1日
ページを公開しました。