![]()
Enabling digital transformations in industries and a society

Why Open Dataspaces: Design Philosophy and the Architectural Paradigm
Release Date:Apr 1, 2026
Digital Architecture Design Center
Digital Architecture Design Center, Information-technology Promotion Agency, Japan (IPA DADC) has published "Why Open Dataspaces: Design Philosophy and the Architectural Paradigm" — a document presenting the design philosophy and architectural paradigm of Open Data Spaces (ODS).
1. Purpose
This document presents the design philosophy of Open Data Spaces (ODS) — an open and scalable foundation for distributed data management, built on organizational and national diversity by design — together with its core architectural paradigm. As used in this document, the general term "Open Dataspaces" refers to a new-generation distributed data management approach and its constituent concepts. Its design draws on the original dataspace papers from the United States (Franklin et al., 2005; Halevy et al., 2006) and data mesh (Dehghani, 2019; Dehghani, 2022) as its core, and incorporates verification through collaborative R&D with private companies and industry groups at commercial scale.
2. Background: The Agentic AI Era and the Potential of Dark Data
For many technology market participants, 2026 marks a pivotal turning point — what may come to be called the "Dawn of Data Scarcity". According to projections by Epoch AI (2024), if major LLMs (Large Language Models) continue training at their current pace, high-quality data could be exhausted between 2026 and 2032 (Figure 1).
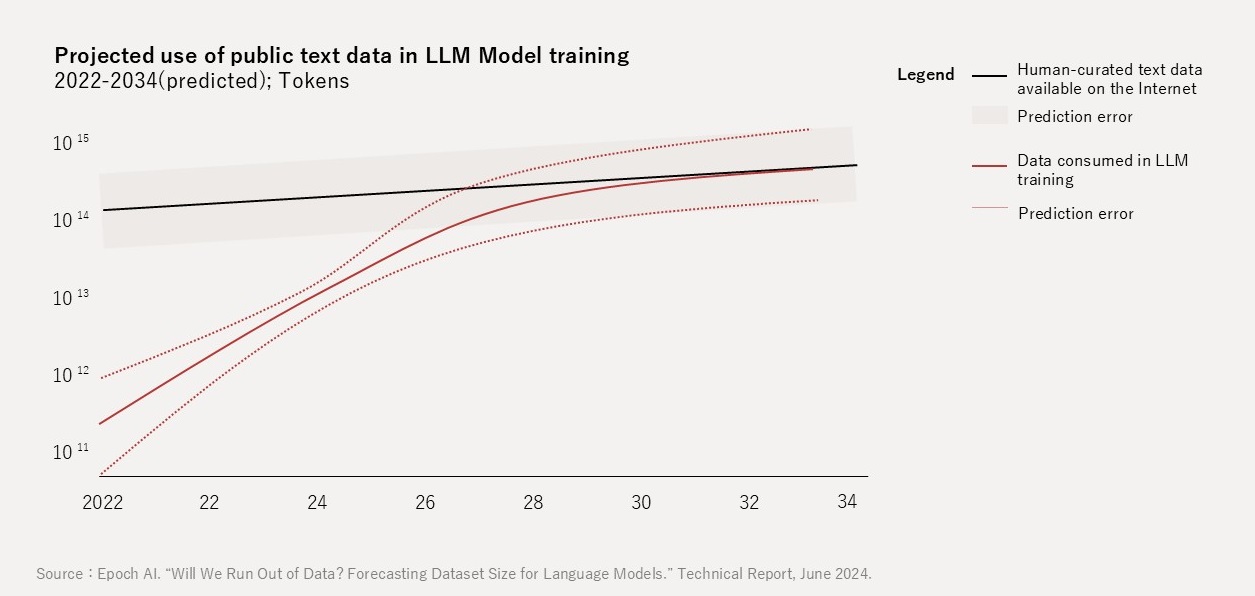
A survey by NEDO (2025) estimates that of the approximately 17.5 ZB of effective real data worldwide (after removing duplicates), roughly 16 ZB remains inside enterprises as "dark data" — data not publicly available on the internet (Figure 2).
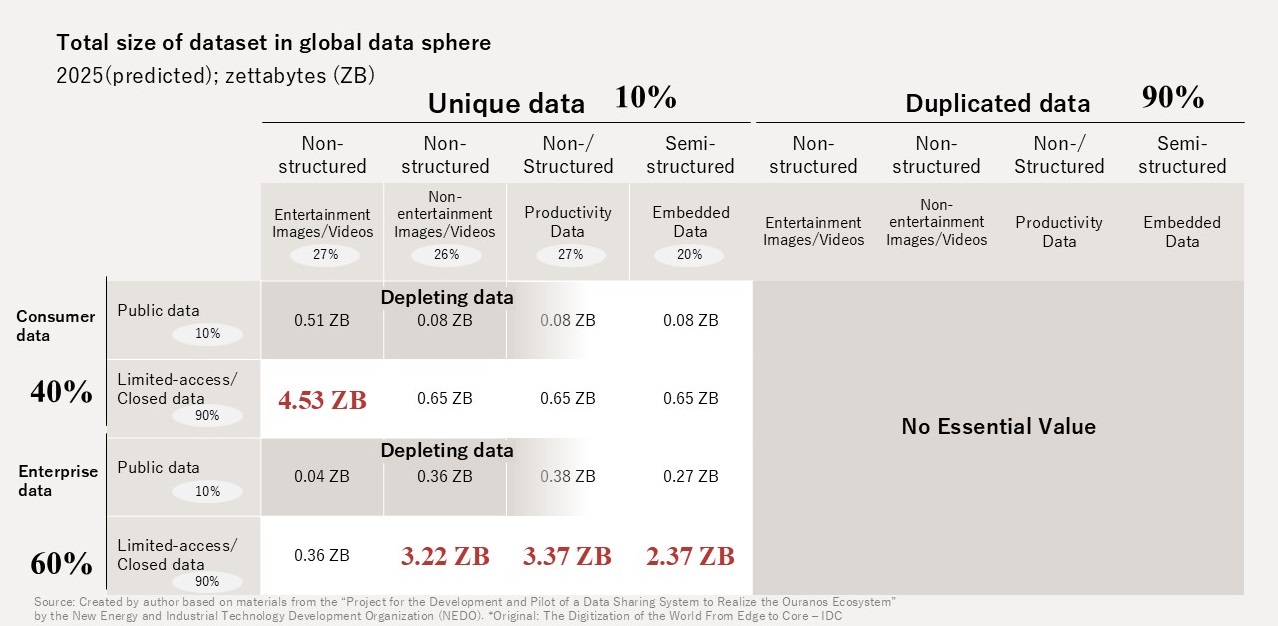
Dark data holds potential value as a resource for both AI training and inference; yet in many cases, organizations cannot readily utilize it. Domain owners can drive organizational value by assigning context to data, providing it as a "product", and controlling its use.
3. Executive Summary
From Aggregation to Distribution: The Paradigm Shift in Data Management
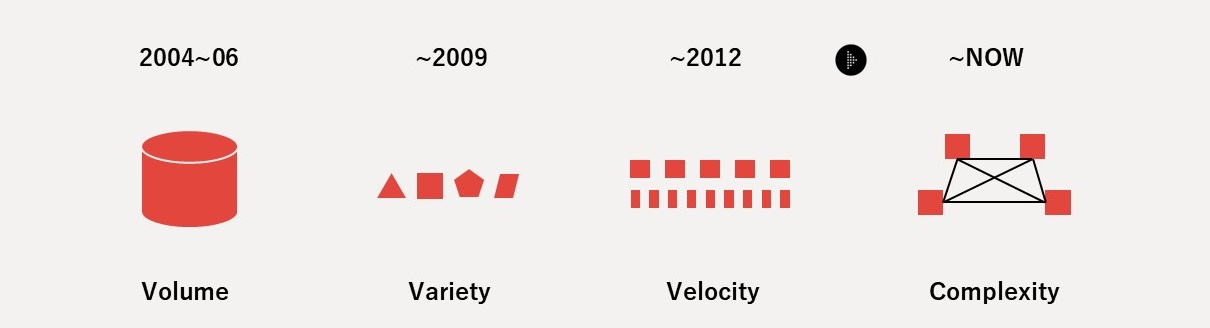
Data management in the 21st century navigated the challenges of the 3Vs (Volume, Variety, Velocity) and now faces the problem of "Complexity". This Complexity is multi-dimensional — spanning not only technical aspects but also industrial, business, organizational, social, legal, and contractual dimensions (Figure 3).
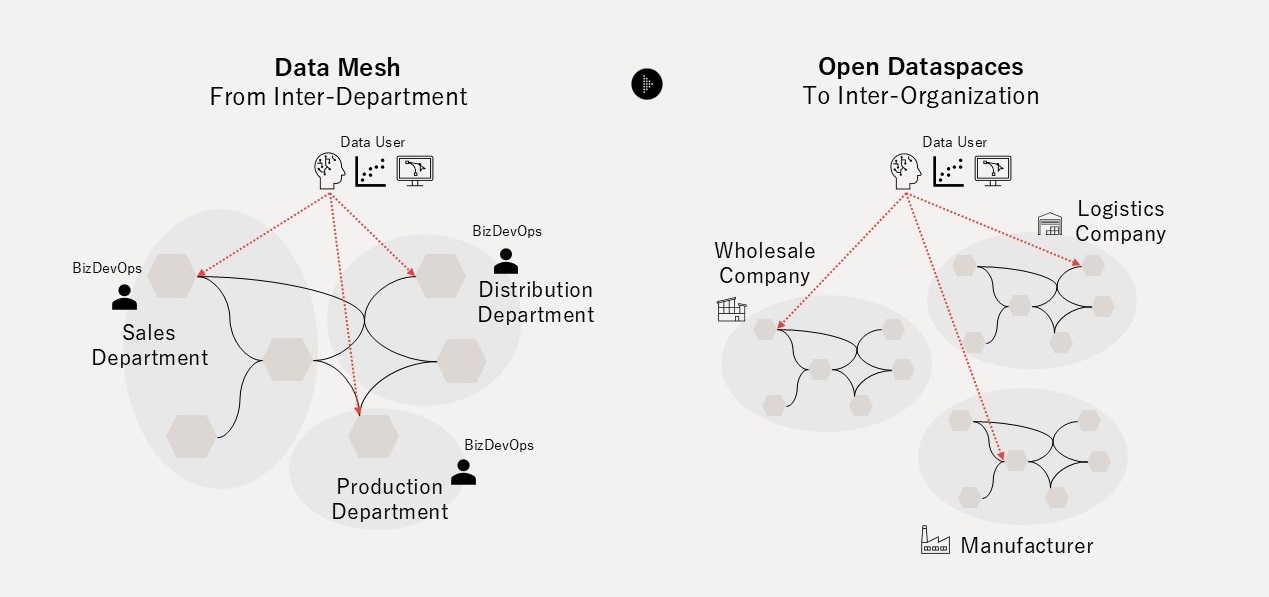
The traditional "Push and Ingest" paradigm has never escaped an aggregation-centric approach that concentrates all data from inside and outside the organization in a single centralized location. As domains diversify and data sources and consumers multiply, the growing volume of data increases technical complexity and raises utilization costs. In the age of Complexity, organizations need a solution for managing dark data — that is scattered, siloed, and exists in heterogeneous structures and meanings — at a reasonable operational cost. The "Serving and Pull" distributed approach that emerged from this problem awareness is data mesh; extending it across organizational and national boundaries gives rise to Open Dataspaces.
From Data Mesh to Open Dataspaces
Data mesh, conceived by Zhamak Dehghani, was a critical turning point in that it returned the responsibility for data from the central data platform back to the business domains. Data mesh asks the domain owners who generate data — PR teams, HR teams, product development teams, and others — to treat data not as a mere by-product of operations but as an explicitly designed and provided product. This made data utilization scalable within the organization without relying on centralized coordination or pre-integration (Figure 4).
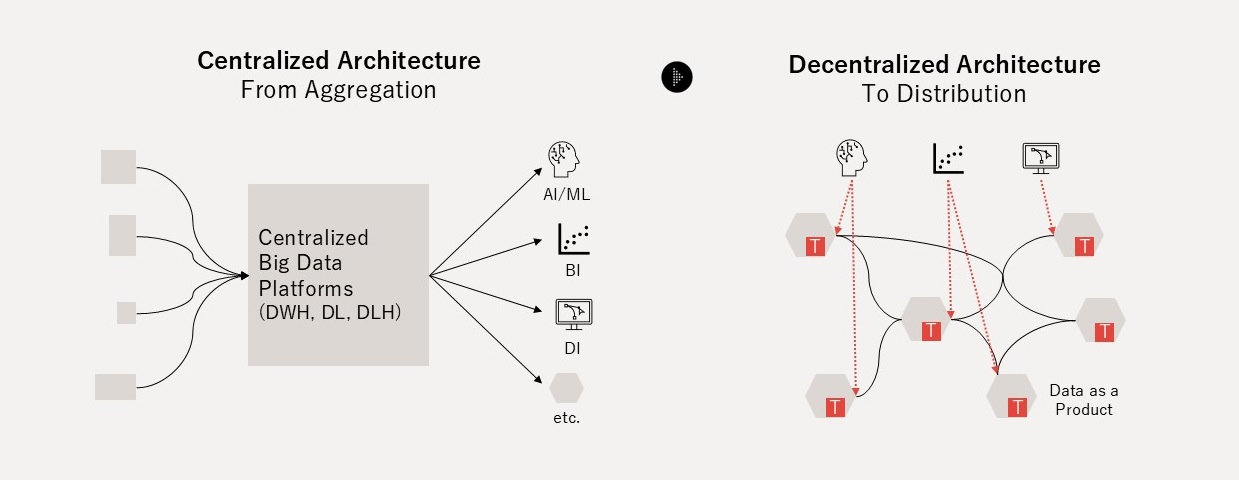
However, data mesh was proposed with an implicit assumption of collaboration across departments within a single organization and has not fully addressed the Governance Complexity problem that emerges when crossing organizational boundaries. Open Dataspaces is a complementary architectural paradigm that inherits the philosophy of Classical Dataspaces (Franklin et al., 2005) and the paradigm of data mesh. It resolves three Governance Complexity problems: (1) Where to get, (2) What to mean, and (3) Who and How to use — enabling distributed data management across organizational and national boundaries (Figure 5).
The Minimum Unit of the Architectural Paradigm: Double-Product Quanta Model (DPQM)
Architectural Quanta (AQ) is the minimum constituent unit of architecture in distributed data management. To address the interoperability problem of the Data Product — the AQ of data mesh — Open Dataspaces newly introduces the concept of "Ontology Product", which has a symmetric relationship with Data Product. Open Dataspaces designates both Data Product and Ontology Product together as the constituent unit AQ. This AQ paradigm is called the "Double-Product Quanta Model (DPQM)" (Figure 6).
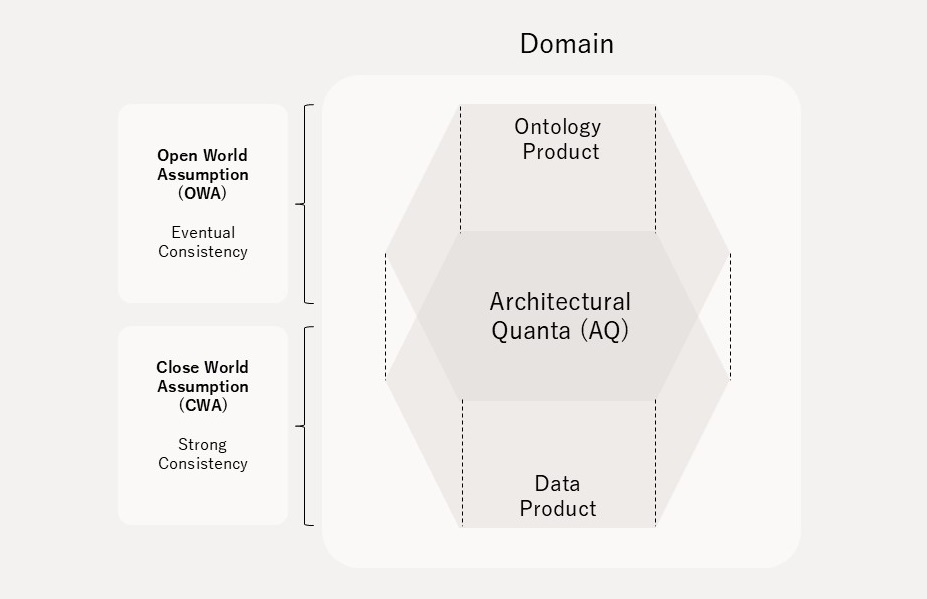
Open Dataspaces adopts a two-layer structure: the Open World Assumption (OWA) — "what cannot be known as true is not false" — governs Ontology Product, while the Closed World Assumption (CWA) is selectively introduced for Data Product. This design bridges the trade-off between the expectations of data providers and consumers. Open Dataspaces adopts the technical principle of "Schema Flexible" — instances (data) come first, and designers attach meaning afterward. This represents liberation from the constraints of set theory presupposed by Edgar Codd's relational model.
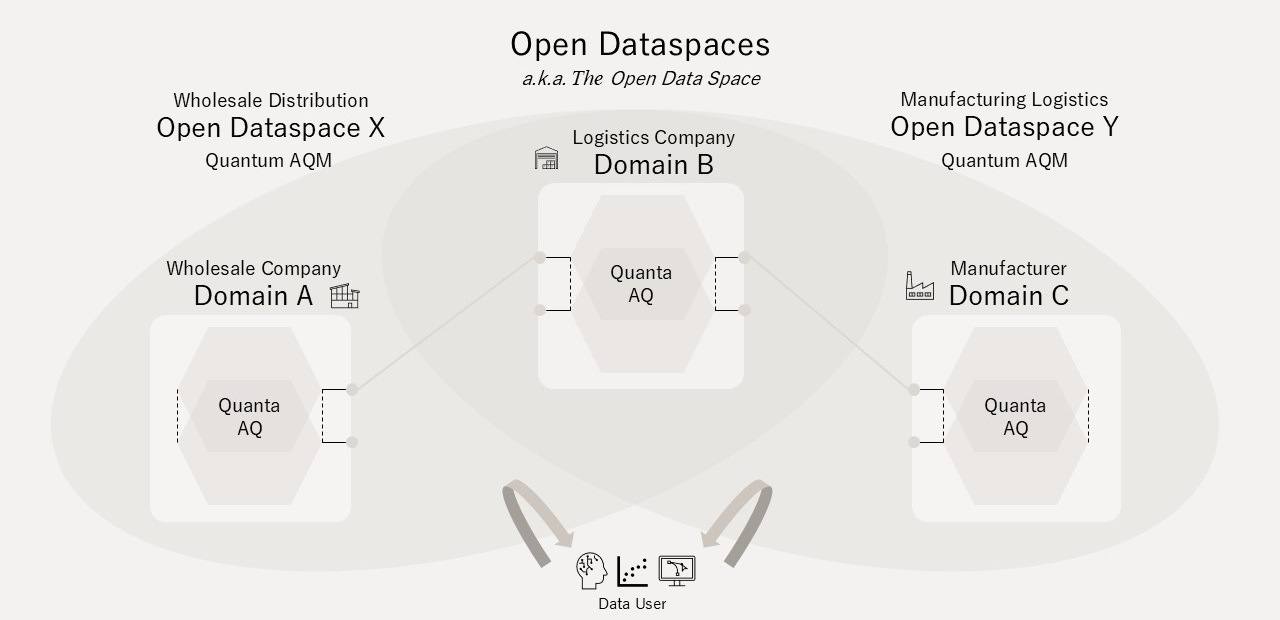
The Structure of Open Dataspaces
(An) Open Dataspace is an Architectural Quantum (AQM) composed of two or more AQs. For example, the product domain AQ of a wholesale company and the warehouse domain AQ of a logistics company together form a Wholesale Distribution Dataspace (AQM); likewise, adding the production domain AQ of a manufacturing company forms a Manufacturing Logistics Dataspace (AQM).
An Open Dataspace is dynamically and plurally composed. If a manufacturing company and a wholesale enterprise form an Open Dataspace for supply-demand optimization, it would encompass the AQs of both companies. The totality of such plurally and multi-layered set relationships is referred to as "Open Dataspaces" or "The Open Dataspace" (Figure 7).
The Three Pillars of the Architecture (DAD, OSI, IUC)
The defining characteristic of the Open Dataspaces paradigm is that it realizes transparent Single Source of Truth (SSOT) and a value-return mechanism for domain owners (as data providers) through a distributed architecture with three major pillars (Figure 8), premised on cross-organizational and cross-border operation and the presence of Agentic AI.
-
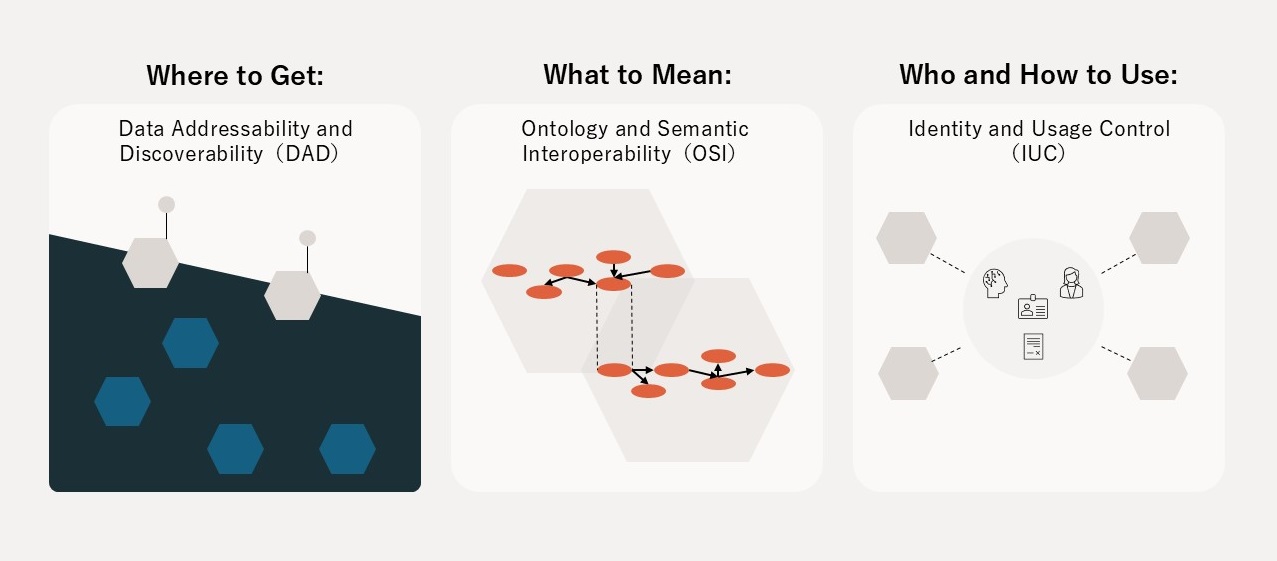
Figure 8 The Three Pillars of Open Dataspaces' Distributed Architecture
- 1. Ontology and Semantic Interoperability (OSI)
-
Open Dataspaces adopts DPQM, which explicitly separates the Information Model from the Data Model. Separating the information model from the data model allows the inevitable evolution of meaning in real operations to be treated as reinterpretation rather than structural destruction. Furthermore, "Dynamic Ontology" — which incorporates LLM-based improvement of the ontological gap — promotes a paradigm shift from Guess to Knowledge as an Agentic AI-native architecture.
- 2. Data Addressability & Discoverability (DAD)
-
Data lacking addressability is equivalent to non-existence. Open Dataspaces exposes two independent interfaces to the outside of the domain — an Ontology Endpoint and a Data Endpoint — and provides globally unique existence proof via IRI (International Resource Identifier), while preserving each domain's internal identifiers. To reach the actual data source, data consumers proceed through a two-stage query process: an Ontology Query (Stage 1) that returns a best effort result for any keyword, and a Data Query (Stage 2) that provides actual access to the data source. A "Data Catalog" in Open Dataspaces is not a static repository but a dynamic viewer generated on demand per query. This combination of Addressability and Discoverability constitutes DAD.
- 3. Identity and Usage Control (IUC)
-
Open Dataspaces treats trust not as an assumption but as a design target — "Trust by Design". Identity is decomposed into three elements: Identity Proofing, Authentication, and Authorization, each with distinct responsibilities. Usage control extends access control to govern the rights and obligations aspects of data handling. Because binding the means of usage control to a single, inflexible technical protocol creates a high risk of becoming a bottleneck for market introduction, Open Dataspaces does not restrict technical means. It provides only interfaces, allowing various methods that do not presuppose jurisdictional or institutional homogeneity.
Design Principles and Service Model
Open Dataspaces adopts three core design principles for realizing the three pillars: (1) Vendor-agnostic, (2) Institution-agnostic, and (3) Product-Like, Service-Oriented Design. Protocols are composed in a loosely coupled manner, with backward compatibility built in at the design stage.
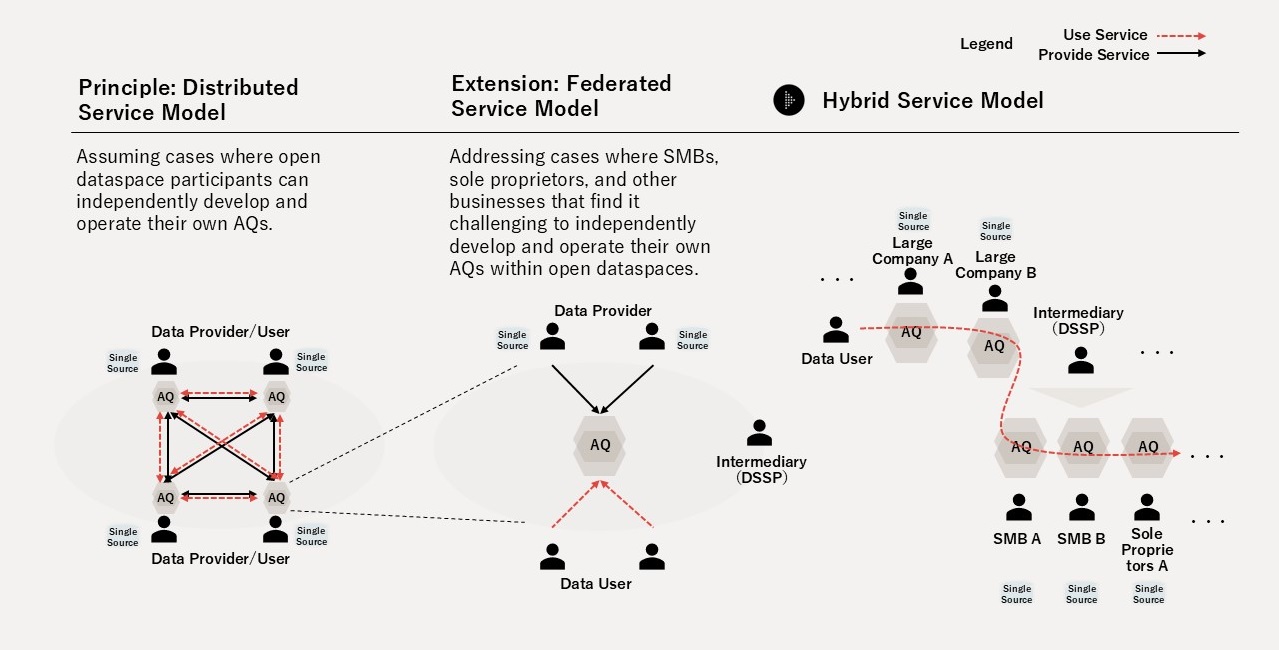
As a service model, Open Dataspaces assumes a "Hybrid Service Model (HSM)" — a mixture of (1) the Distributed Service Model, in which domain owners themselves build a Self-Serve Data Platform, and (2) the Federated Service Model, in which a managed service provider ("Dataspace Service Provider (DSSP)") delivers the basic software stack constituting DPQM on behalf of the domain owner (Figure 9). HSM enables participation in Open Dataspaces by a wide range of actors from large enterprises to SMBs.
4. Download

This document is available for download at the following link:
Publisher
Digital Architecture Design Center, Information-technology Promotion Agency, Japan
Editor & Author
Michitaka TSUDA, Open Data Spaces Chief Architect
Copyright
Information-technology Promotion Agency, Japan
Contact information
Digital Architecture Design Center
-
E-mail
Change log
-
Apr 1, 2026
The page is newly published.