The Context Layer for Agentic Enterprises.
The era of Data Scarcity.@AI knows the world, but it has yet to @understand the domain context.
The era of Data @Scarcity.@AI knows the world, @but it has yet to @understand the @domain context.
The next breakthrough won't come from the web—it lies in your operations: the "real data" your organization generates every day.
Are you locking your data away in a vault, hiding behind "confidentiality"?
Isolated from the outside world, even the most valuable data eventually sinks into silence.
You think you are protecting it. In reality, you are letting it slowly decay.
The key is stewarding your data “AI-ready”.
The key is @stewarding your data @“AI-ready”.
And building a foundation that connects only with those you trust.
Don’t dump it into a massive silo where context is lost.
Never surrender your control to others.
The answer is Open Data Spaces.@Contextualize. Then, unleash.
The answer is Open @Data Spaces.@Contextualize. Then, @unleash.
By enabling distributed and trusted data management,
Knowledge in organizations begins to create new value across boundaries.
Human-ON-the-loop. Then join forces as equals with selected partners.
Only then does data transform into a true asset.
Keep it isolated, or connect to create new value?
The key to evolving together in the global agentic market.
Open Data Spaces.
Open Data Spaces (ODS) is an open and scalable foundation for distributed data, built on organizational and national diversity by design.
What is Open Data Spaces (ODS)?
What is Open @Data Spaces @(ODS)?
Open Data Spaces (ODS) is an open and scalable foundation for distributed data management across enterprises and industries, built on organizational and national diversity by design.
As the foundation of Agentic AI, ODS provides the open architecture and protocols for managing business-specific data and context in a trustworthy manner across domains and organizations while keeping them distributed.
No lock-in to any specific cloud, platform, or vendor.

Not a closed paradigm optimized for any specific jurisdiction's regulations, but adaptable globally.
Service-
Oriented
Design
Always asking the market one critical question: does this contribute to Make Money or Save Money?
In the era of Agentic AI, the "context" of data is the ultimate key to success.
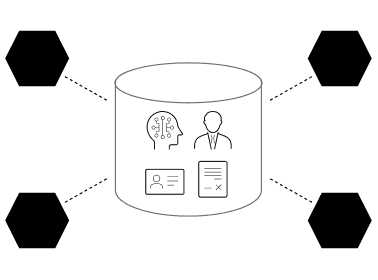
As a “context layer” powered by a distributed data management architecture, ODS delivers both transparency and control. For data consumers (Agentic AI), it provides clarity on whether data exists, where it is located, and what it means. For data providers (Domain Owner), it ensures governance over who can access which data, and for what purpose.
Integrating ODS into post-training data pipelines transforms AI from a simple "answering engine" into a trusted "action engine."
The "Open" in Open Data Spaces does not mean making everything public. Instead, it signifies "fairness” striking a perfect balance between transparency and control. ODS is not about unrestricted access; it is about opening up data in a manageable and governed way.
Design Philosophy
Design @Philosophy


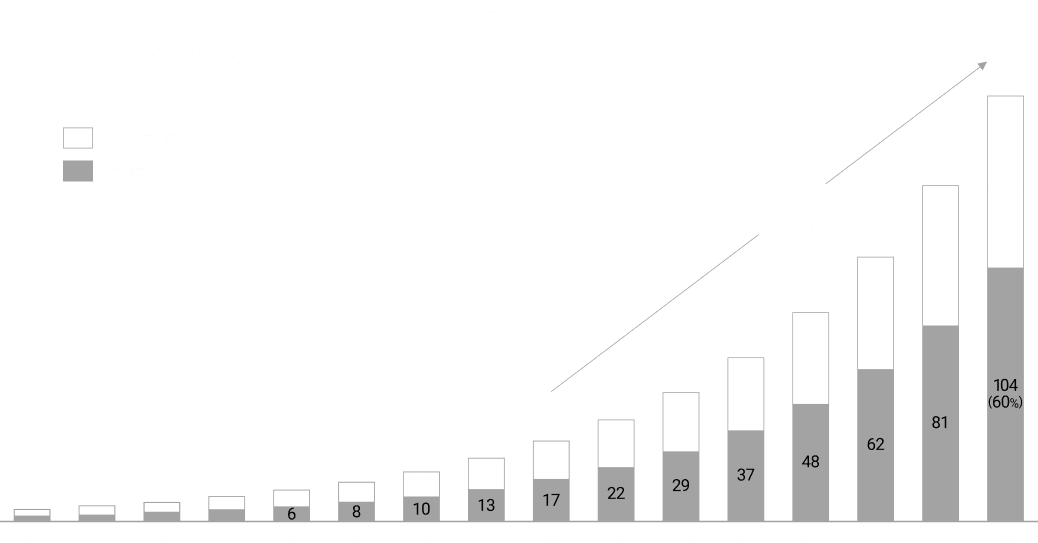

Data is Eating
the World
Real Data and Context
It is projected that high-quality data supporting AI training could be exhausted between 2026 and 2032. This brings into focus the vast reserves of real data held -- and largely untapped -- within enterprises. The key to transforming that dark data into valuable corporate capital is giving it domain context: the background, meaning, and operational circumstances in which it was created. Productizing data enriched with frontline context is how organizations drive enterprise value in the Agentic AI era.
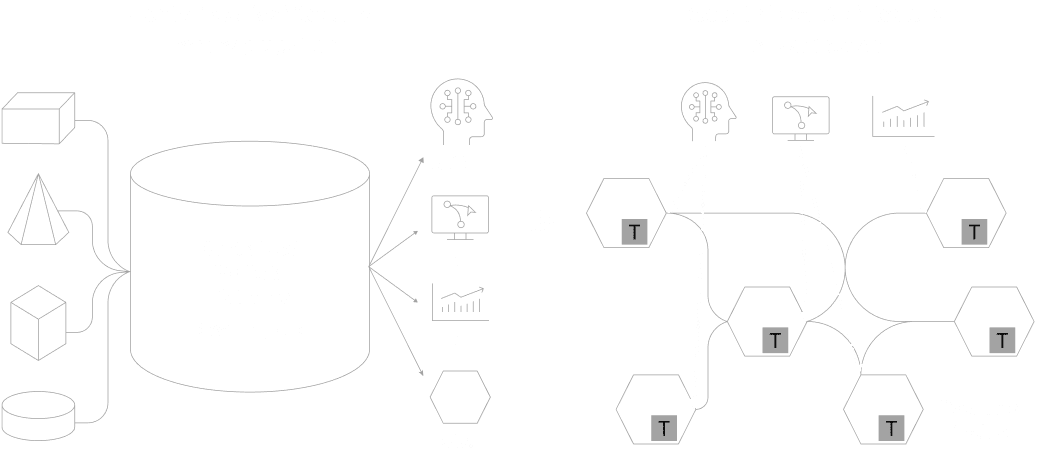
From
Aggregation
To Distribution
From Aggregation to Distribution
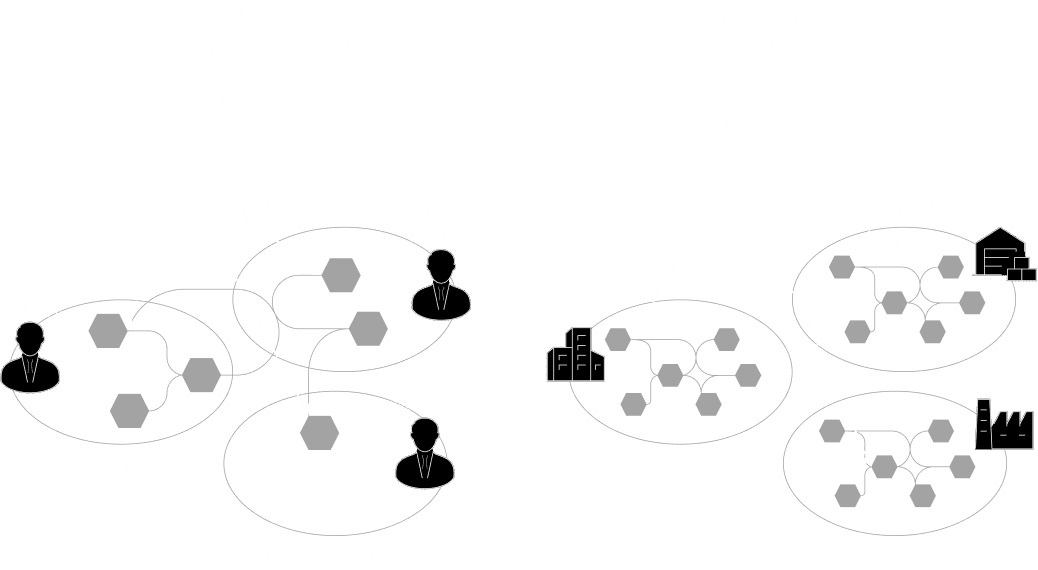
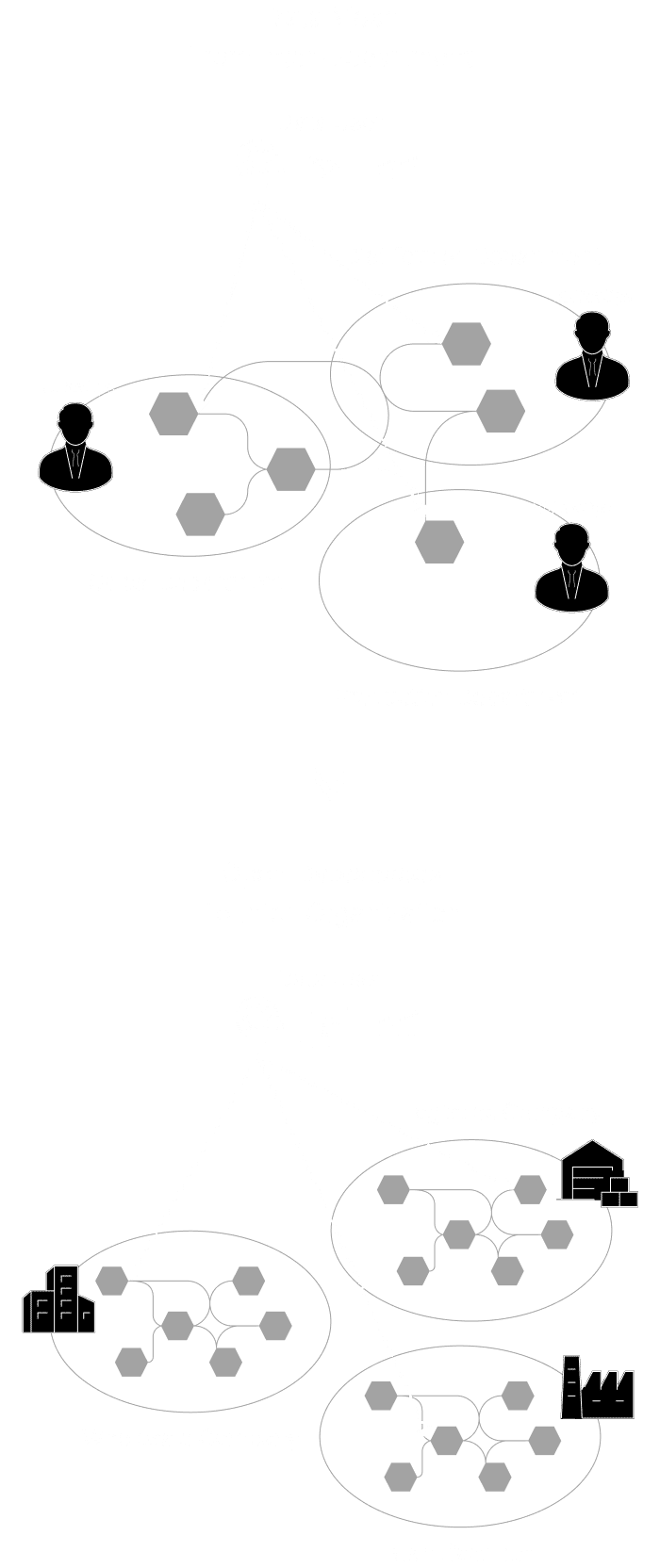
Conventional centralized data management ― concentrating all data in one place ― has reached its operational and cost limits. Going forward, a distributed approach is required: one where individual domains manage and provide their own data. This shift accelerates data utilization within and across departments. But seamless data management across organizational and national boundaries requires a more advanced paradigm.
From Data Mesh
To Open
Dataspaces
A New Paradigm
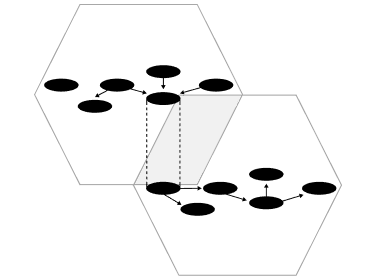
Open Dataspaces inherits the architectural paradigm and four foundational principles of data mesh ― accepting the paradigm shift from the traditional “Push and Ingest” model to a “Serving and Pull” model, and adopting a data management approach based on Domain-Driven Design (DDD). The most significant difference from data mesh is that Open Dataspaces is a paradigm designed for inter-organizational data management ― going beyond the inter-departmental scope.
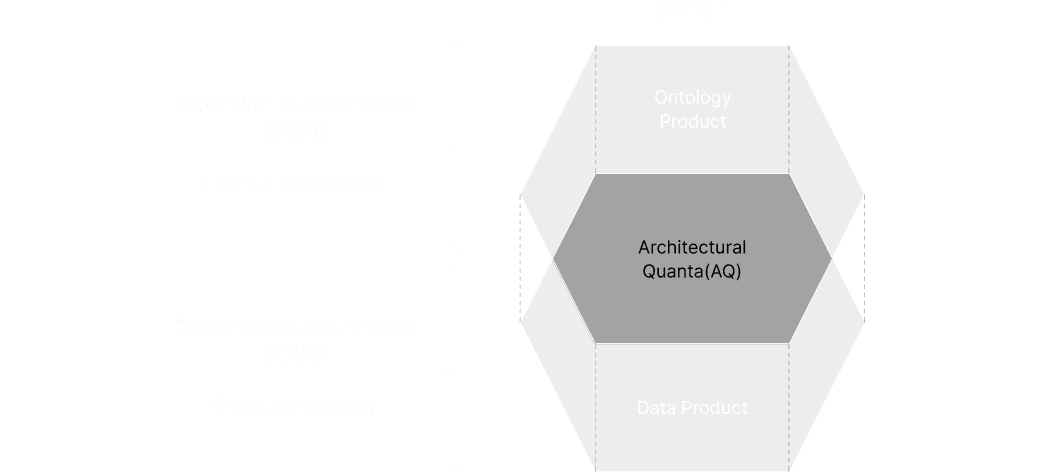
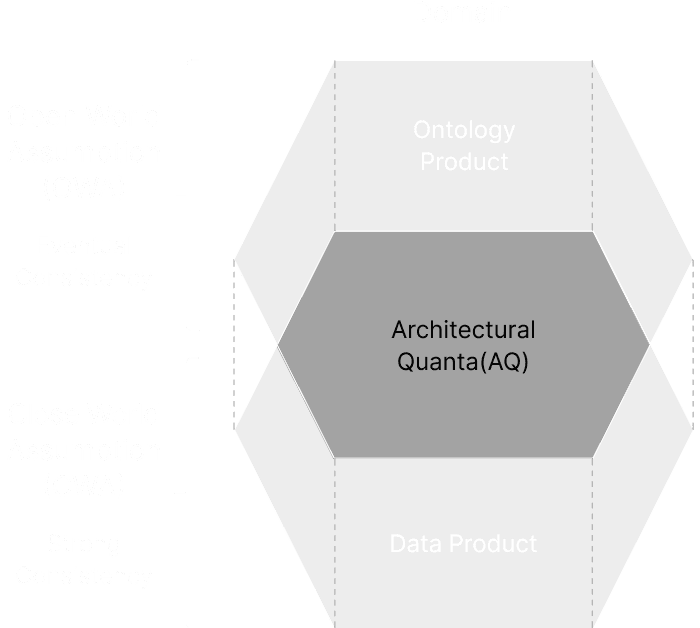
Double Product
Quanta
Model(DPQM)
Balancing Openness and Rigidness
Managing data securely and flexibly across organizational and national boundaries requires a mechanism that treats data and domain context as inseparable partners.
The architecture employs a dual-layered approach: embracing diverse data through flexible rules that accommodate unknown information (Open World Assumption), while ensuring reliability at the point of use through strict validation (Closed World Assumption). This structure ― balancing openness with rigidness ― enables secure, scalable distributed data management.
ODS in Action: Proven Commercial Success
It is not a theoretical concept but in active commercial use. ODS has already been scaling across multiple pioneering projects, demonstrating its reliability in real-world environments.
Battery & Automotive
2024~ (operating & scaling)
Unmanned Aircraft Systems & Traffic Management
2025~ (operating & scaling)
Chemical & Circularity Management
2026~ (implementing)
―No, market chooses our architecture.
The Three Pillars of Open Dataspaces’ Distributed Architecture
Solving the three Governance Complexity problems that arise in cross-organizational distributed data management.
- Where is the data in the first place?
- Does this data refer to the same thing as that data?
Discoverability(DAD)
- What does this data mean?
- Is the meaning of this data consistent with that data?
Interoperability(OSI)
- Who is trying to access the data?
- Who can access this data?
- How must this data be used?
Control(IUC)
The evolution of Agentic AI depends on its ability to understand "Context."
Open Dataspaces enables Agentic AI to move beyond statistical guesswork and into genuine knowledge-based inference.
From Inter-Department To
Inter-Organization

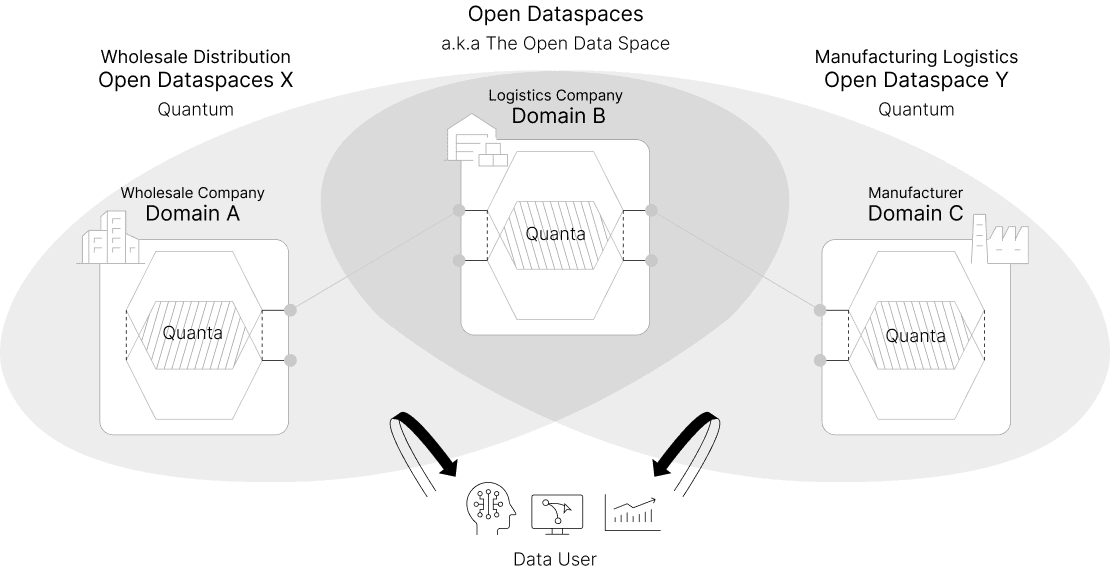
While data mesh enables cross-departmental data management within a single organization, Open Dataspaces extends this to inter-organizational data management across corporate and national boundaries. For example, wholesalers, logistics providers, and manufacturers can each provide data "only to the partners they choose, only the portions they choose, and only in the manner they choose."
Dynamic Ontology
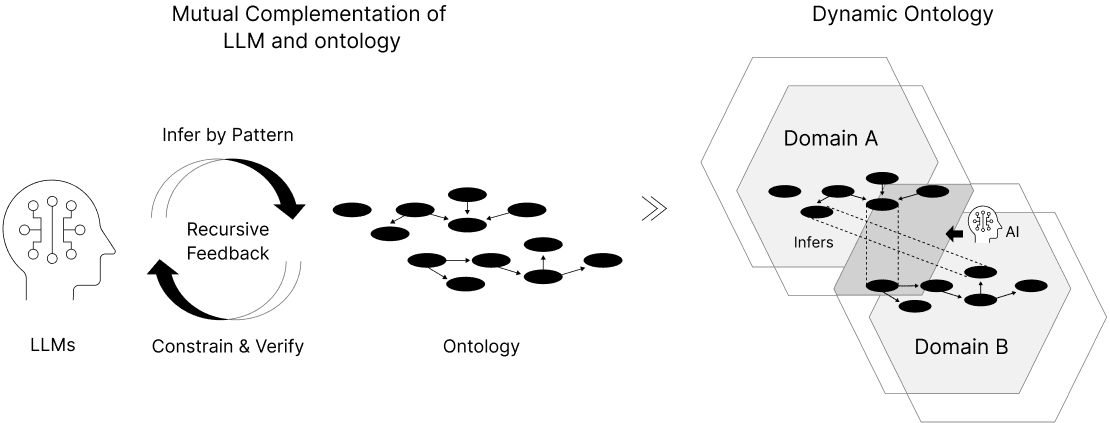
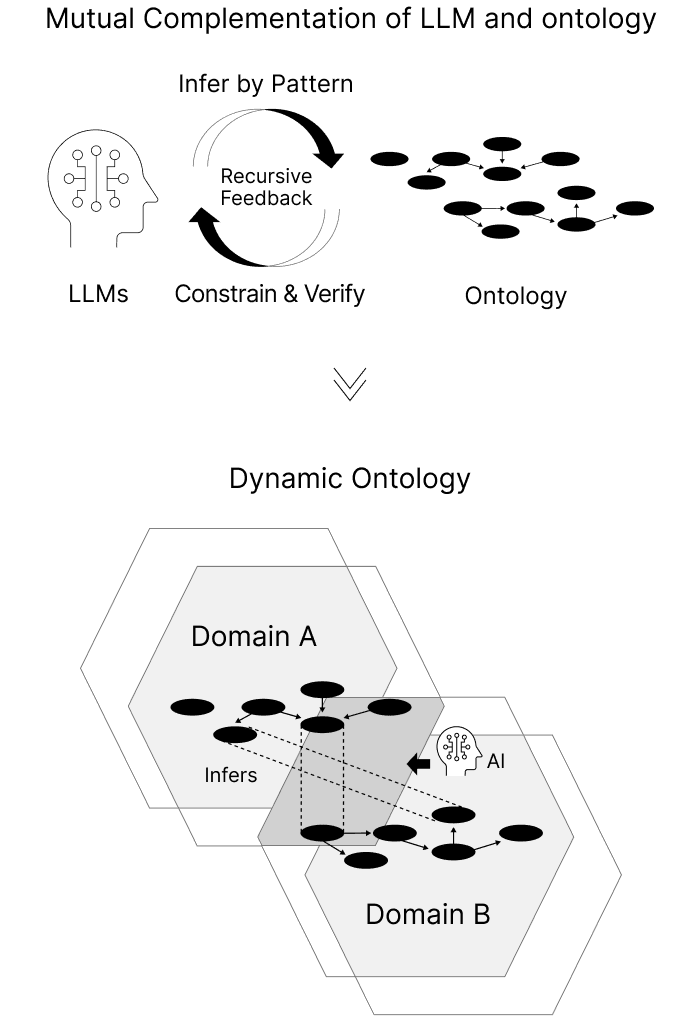
By decoupling data "semantics" from its "structure", Open Dataspaces allows meaning to evolve without breaking the underlying systems. Even when definitions differ across organizations, LLMs infer semantic connections, which are then validated and refined through logical ontological rules. This continuous cycle ensures that data sharing never stops—even with incomplete datasets. Through this process, "ambiguous guesses" are transformed into "verifiable knowledge," maturing the ecosystem during actual operation.
The Concept behind the Logo


The distinctive structure of DPQM (Data Product Quanta Model) is at the heart of our Visual Identity (VI).
Please carefully read and comply with the Open Data Spaces official website and usage guidelines regarding logo use.
The Open Data Spaces logo, icons, symbols, and designs may not be used without prior written permission from the rights holder.
FAQ
What are the official brand notation rules for Open Data Spaces (ODS)?
Can expressions such as “based on”, “conforms to”, “compliant with”, or “certified by” be used when
referring to ODS artifacts?
We are planning to adopt ODS. Which artifacts should we read first?
- For those considering offering ODS software or data management services:
ODS Guidebook for Developers - For those considering using or implementing ODS services:
ODS Guidebook for Users - For those who want to understand design philosophy:
Why Open Dataspaces: Design Philosophy and the Architectural Paradigm
We are considering implementing ODS. Do you provide an SDK or similar tools?
Please refer to the links below for details.