Agentic Enterpriseのコンテキストレイヤー
データ枯渇時代。@世界の常識を知るAI も、@現場の⽂脈はまだ知らない。
データ枯渇時代。@世界の常識を知るAI@も、現場の⽂脈はまだ@知らない。
次に必要なのはWeb 上の情報ではなく、
あなたの組織が⽇々の業務で⽣み出す「現場のリアルなデータ」だ。
「機密情報だから」と、データを⾦庫の奥にしまい込んでいないだろうか。
どんなに貴重なデータも、外の世界から遮断し、
ただ溜め込んでいるだけでは、静かに埋没してゆく。
守っているつもりで、実はゆっくりと腐らせている。
⼤切なのは、@データをAI が理解できる状態にすること。
⼤切なのは、@データをAI が理解でき@る状態にすること。
そして、信頼できる相⼿とだけつながれる仕組みを持つこと。
巨⼤なタンクに放り込んで、⽂脈を失わせてはならない。
管理を他⼈に委ね、⾃らの主導権を⼿放してはならない。
その解こそ、Open Data Spaces。@眠れるデータに⽂脈を与え、解き放て。
その解こそ、Open Data Spaces。@眠れるデータに⽂脈を与え、解き放て。
データを信頼のもと分散して管理できるようにすることで、
組織の知恵は、業界や国を超えて新たな価値を⽣み出し始める。
自社のデータは自社で守り、選び抜いたパートナーと対等に手を結ぶ。
そうして初めて、データは誇りある「資産」へと変わるのだ。
閉ざして終わるか。つなげて新たな価値をつくるか。
グローバル市場でともに進化するための鍵。
それが、Open Data Spaces。
Open Data Spaces (ODS)は、国や組織ごとの多様性を尊重する、
オープンでスケーラブルな分散データマネジメントの技術コンセプトです。
Open Data Spaces (ODS)とは?
Open Data @Spaces (ODS)@とは?
Open Data Spaces (ODS) は、国や組織ごとの多様性を尊重する、オープンでスケーラブルな分散データマネジメントの技術コンセプトです。
ODSはAgentic AI導入の基盤となる業務特有のデータや文脈を、信頼性高くドメインや組織を横断して分散したまま管理するためのオープンアーキテクチャやプロトコルを提供します。
縛られない
特定のクラウド、特定のプラットフォーム、特定の企業に縛られないこと

縛られない
特定の国・地域の制度だけに最適化された閉じた仕組みではなく、グローバルで利用可能な設計になっていること
サービス
志向の設計
Make Money, Save Moneyに資するか?をマーケットに常に問い続けながら設計すること
つまり、Agentic AI時代において
「データの持つ文脈(コンテキスト)」こそが、成功の要です。
分散データマネジメントアーキテクチャであるODSは、コンテキストレイヤーとして、
データの利用者視点では、「データは存在し」「どこにあり」「何を意味するのか」という透明性を、
データの提供者視点では、「誰が」「どのデータを」「何の目的で使えるのか」という制御性を提供します。
ODSを事後学習データパイプラインに導入することで、AIを単なる「回答エンジン」から、信頼できる「アクションエンジン」へと変革することに繋がります。
Open Data Spacesの「Open」は、「すべてを公開する」という意味ではありません。
「透明性と制御性」を両立した「公平性を持っている」、という意味での「Open」です。
無制限に公開するのではなく、管理可能な形で開く。それがOpen Data Spacesです。
Design Philosophy
Design @Philosophy



Data is Eating
the World
「リアルデータ」と「文脈(コンテキスト)」
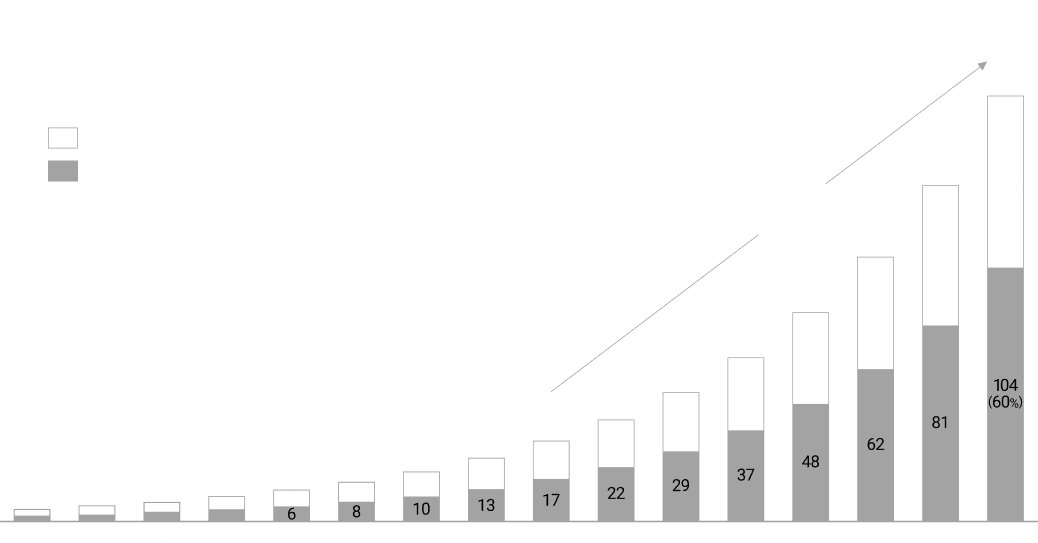
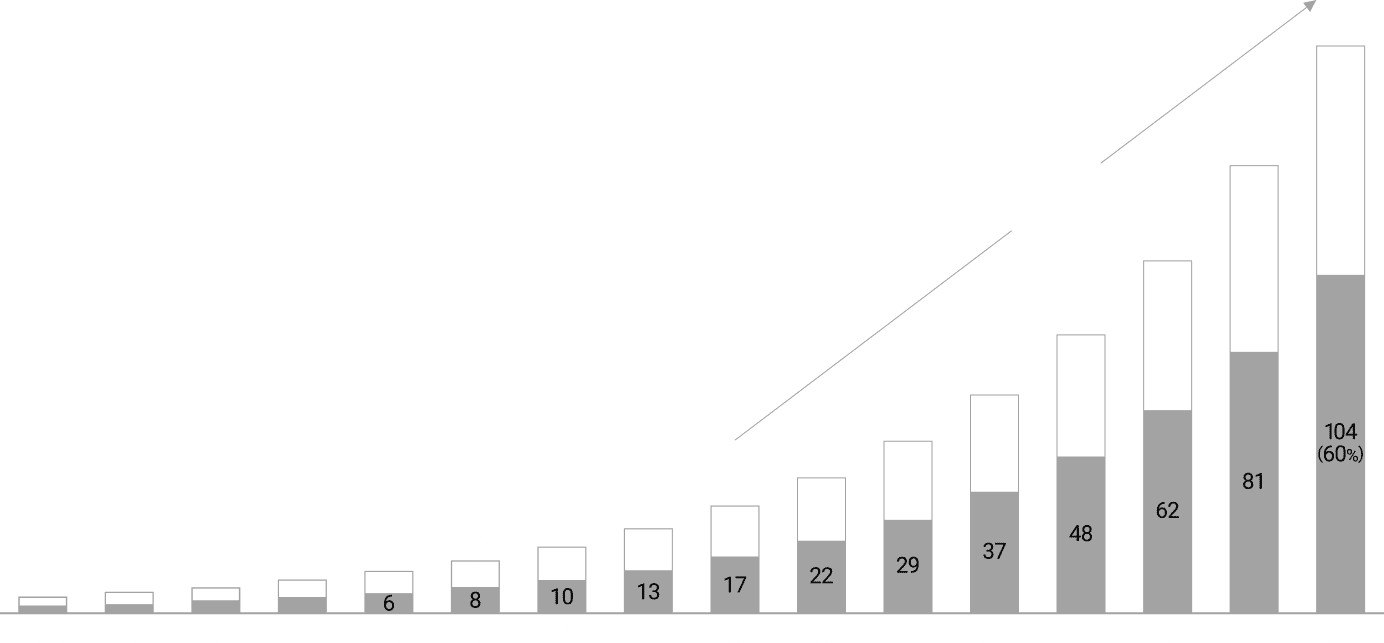
AIの進化を支える高品質な学習データは、2026年から2032年の間に枯渇すると言われています。そこで注目されるのが、企業内に眠る膨大なリアルデータです。この未活用のデータを価値ある経営資本に変える鍵は、データが生まれた背景や意味(ドメインコンテキスト)を明確にすること。現場の文脈と紐づけてデータを“商品化”することが、これからのAgentic AI時代における企業価値向上につながります。
From
Aggregation
To Distribution
集約から分散へ
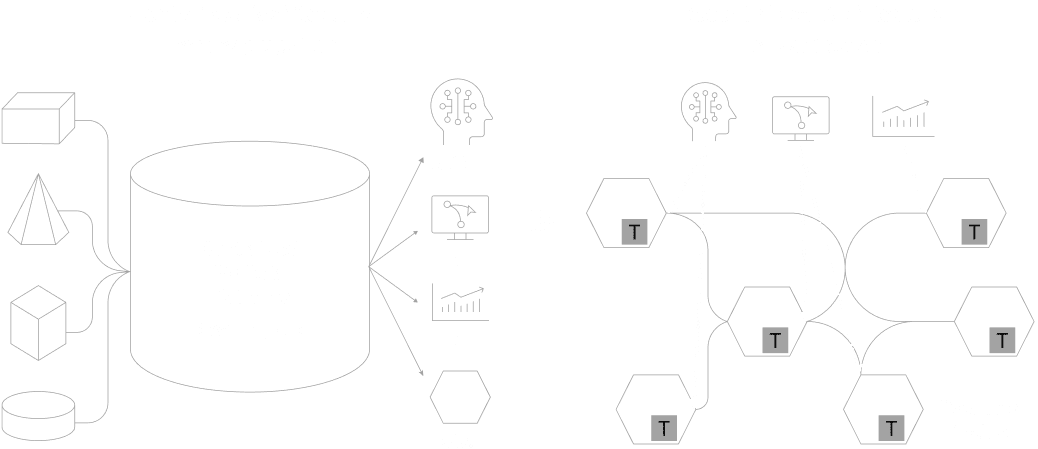
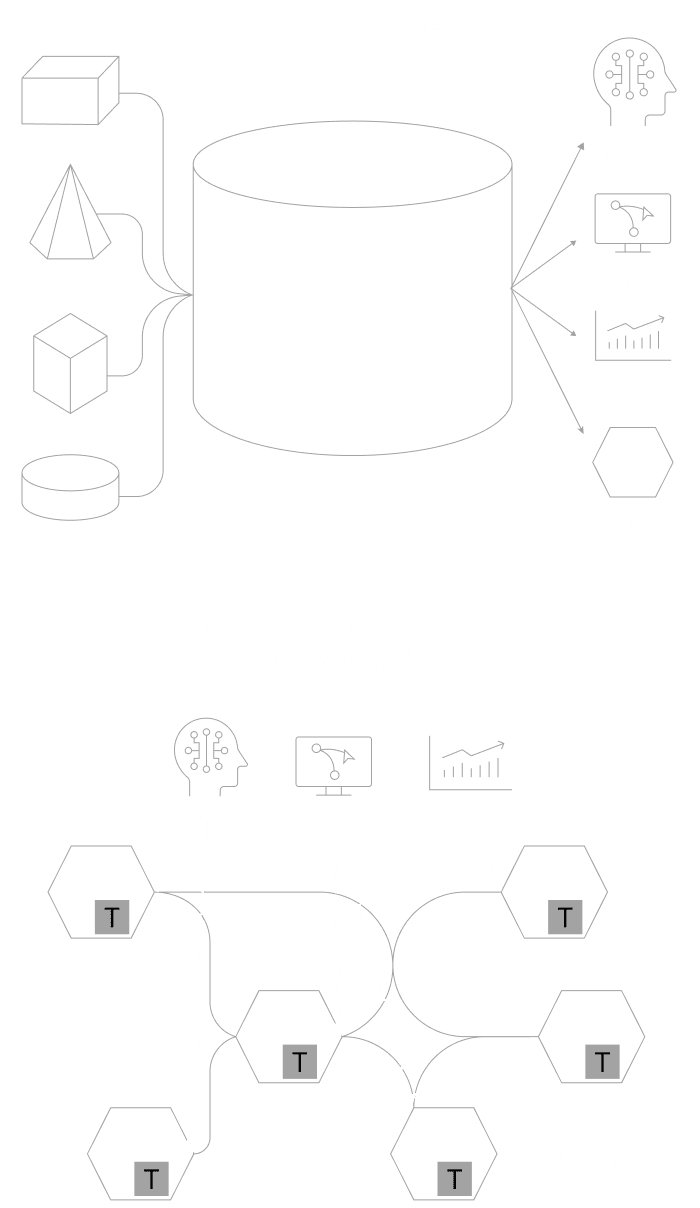
これまで主流だったデータを中央に一極集中させる管理手法は、コストや運用の限界を迎えています。これからは、現場(ドメイン)が自らデータを管理・提供する「分散型」のアプローチが求められます。これにより組織内・部門間におけるデータ活用は進みますが、組織や国境を越えたデータマネジメントには、さらに進化した次世代のパラダイムが必要になります。
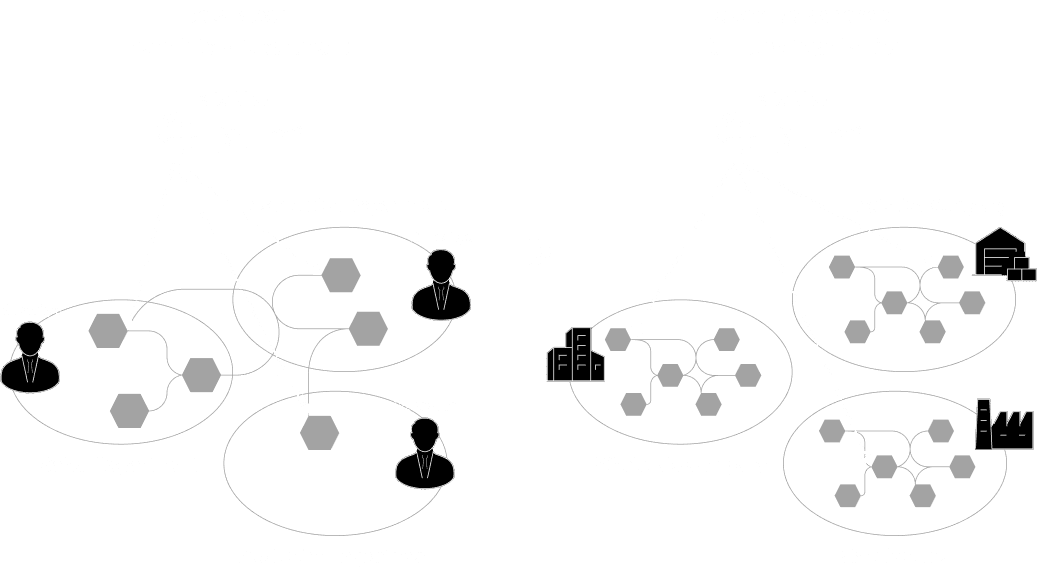
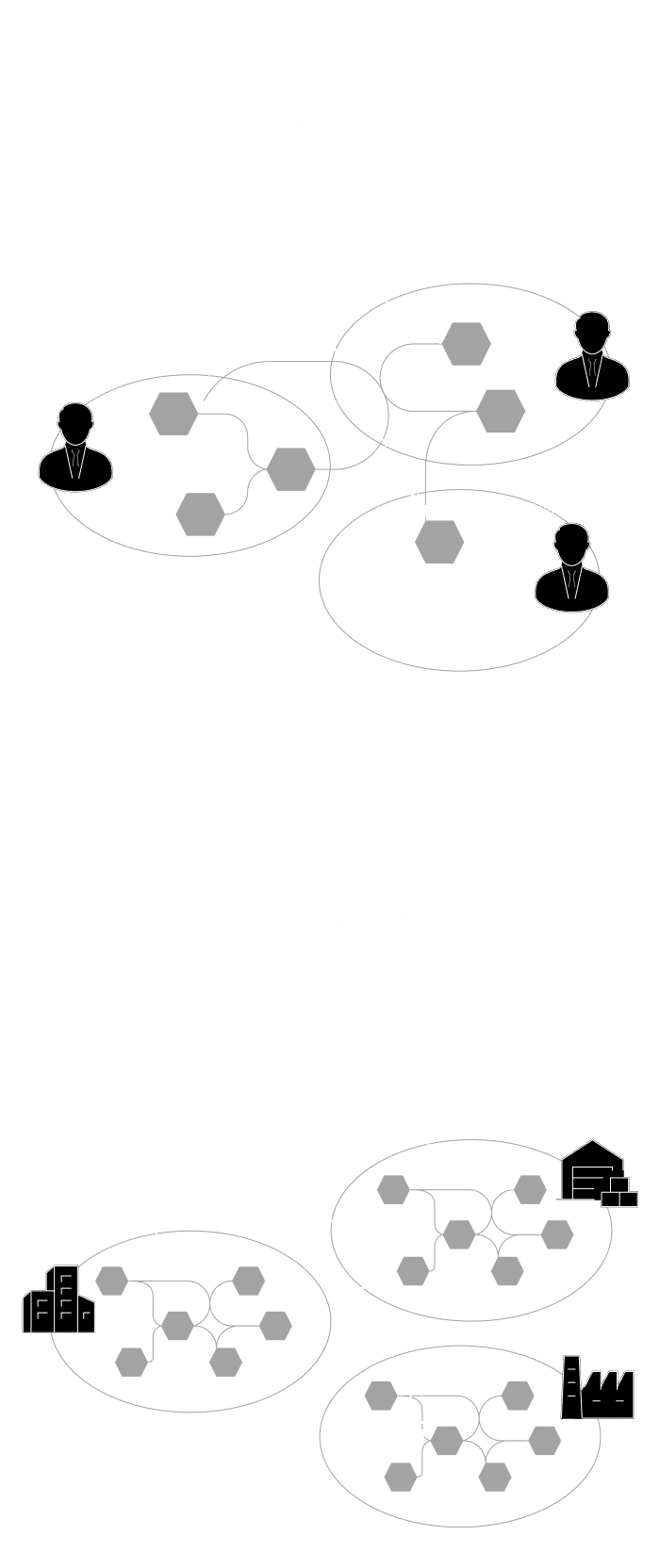
From Data Mesh
To Open
Dataspaces
新たなパラダイム
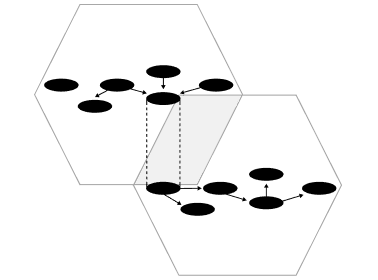
Open Dataspacesは、Data Meshのアーキテクチャパラダイムと4つの基本原則を承継しています。つまり、伝統的な Push and Ingest 型ではなく、Serving and Pull型へのパラダイムシフトを受け入れ、「Domain-Driven Design(DDD)」を基調としたデータマネジメント方式を採用しています。Data Meshとの最大の差分は、部門間(Inter-Department) からさらに組織横断(Inter-Organization) のデータマネジメントを念頭に置いたパラダイムであるということです。
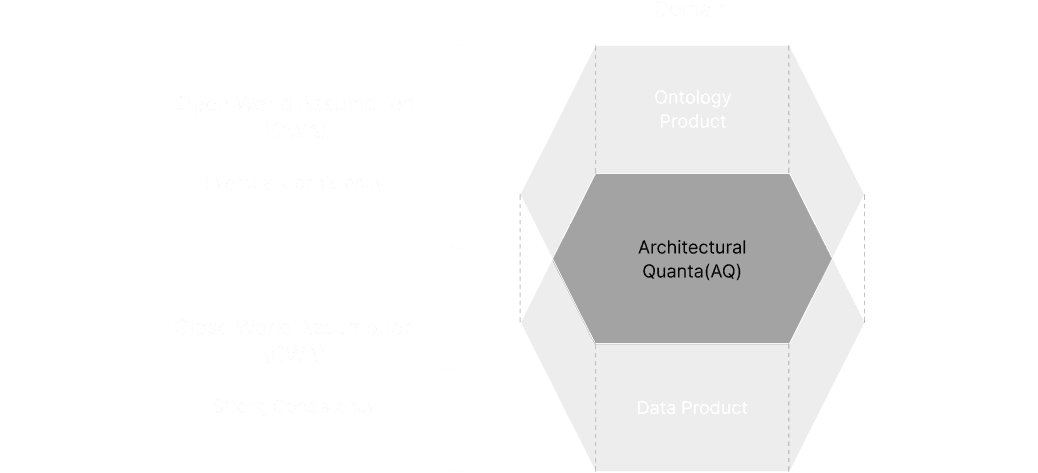
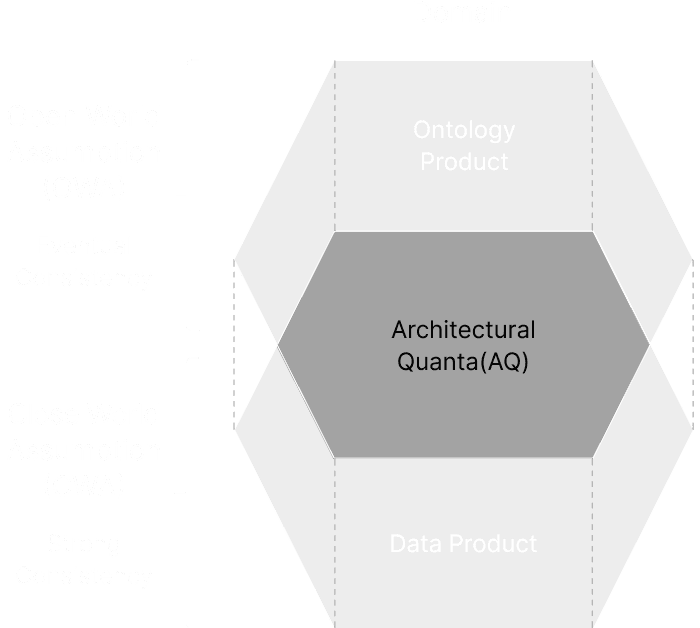
Double Product
Quanta
Model(DPQM)
開放性と厳格性の両立
組織や国境を横断して、データを安全かつ柔軟にマネジメントするためには、データとドメインコンテキストを対等な関係で扱う仕組みが重要です。未知の情報も許容する柔軟なルール(開世界仮説)で多様なデータを受け入れつつ、利用時には厳密なルール(閉世界仮説)で信頼性を担保します。この開放性と厳格性を両立する二層構造が、信頼性と拡張性の高い分散データマネジメントを可能にします。
すでに商用利用が進むODS。
構想段階ではなく、すでに複数の先行事例で採用されています。
自動車・蓄電池分野
2024年から本格運用・拡大中
無人航空機運航管理分野(ドローン航路)
2025年から運用拡大予定
化学物質・資源循環分野
2026年から実装開始予定
しているのか?
答えはシンプルです。
私たちが市場を説得しているのではなく、市場がこのアーキテクチャを選んでいるからです。
Open Dataspaces アーキテクチャ3つの柱
組織や業界を横断した分散データマネジメントで生じる3つの問題に解決策を提供します。
- そもそも、どこにデータがあるのか?
- そのデータは、このデータと同一のものを指し示しているか?
ディスカバリー
Discoverability(DAD)
- そのデータは何を意味するか?
- そのデータの意味は、このデータの意味と整合しているか?
セマンティック相互運用性
Interoperability(OSI)
- データにアクセスしようとしているのは誰か?
- 誰がそのデータにアクセスできるのか?
- そのデータはどう使わなければならないか?
利用制御
(IUC)
Agentic AIが機能するためには、単なるデータだけではなく現場固有の「コンテキスト(文脈)」が必要です。
ODSによりAgentic AIは単なる推測を超えて推論が可能となります。
From Inter-Department To
Inter-Organization

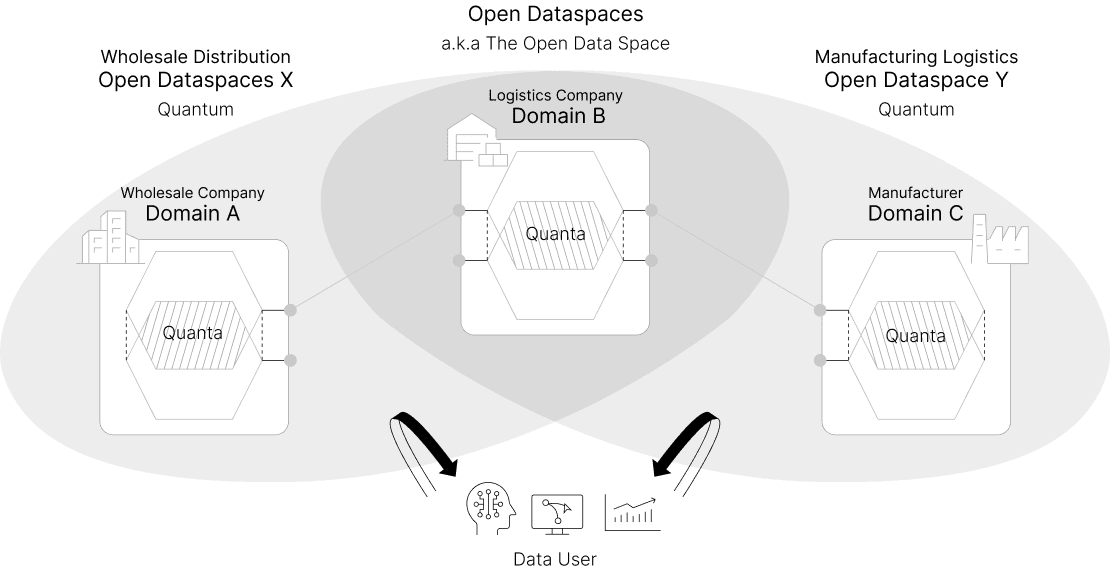
Data Meshでは組織内の部門を跨いだデータマネジメントを前提としますが、Open Dataspacesでは組織を跨いだデータマネジメントを可能にします。
例えば、卸売業者、物流業者、製造業者などがお互いに必要とするデータを自分が「望む相手だけに、望む部分だけ、望む方法で」提供できる環境を提供します。
Dynamic Ontology
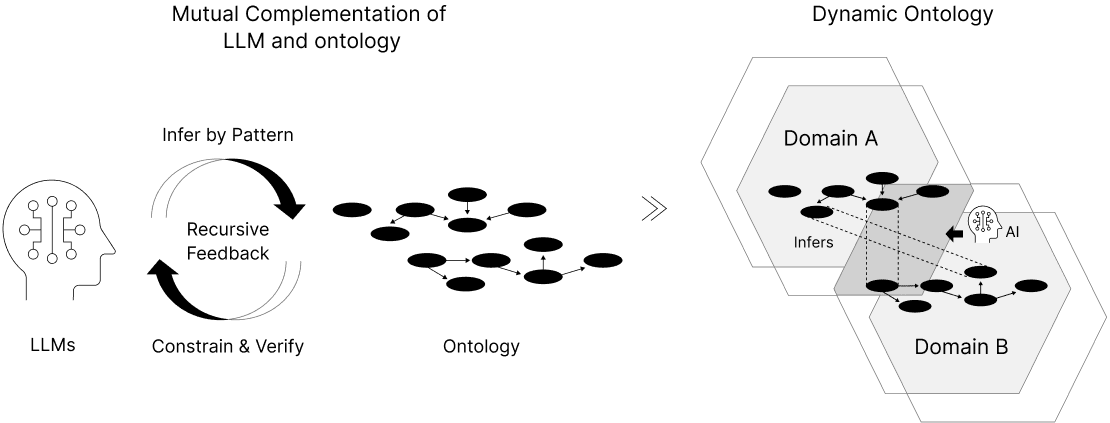
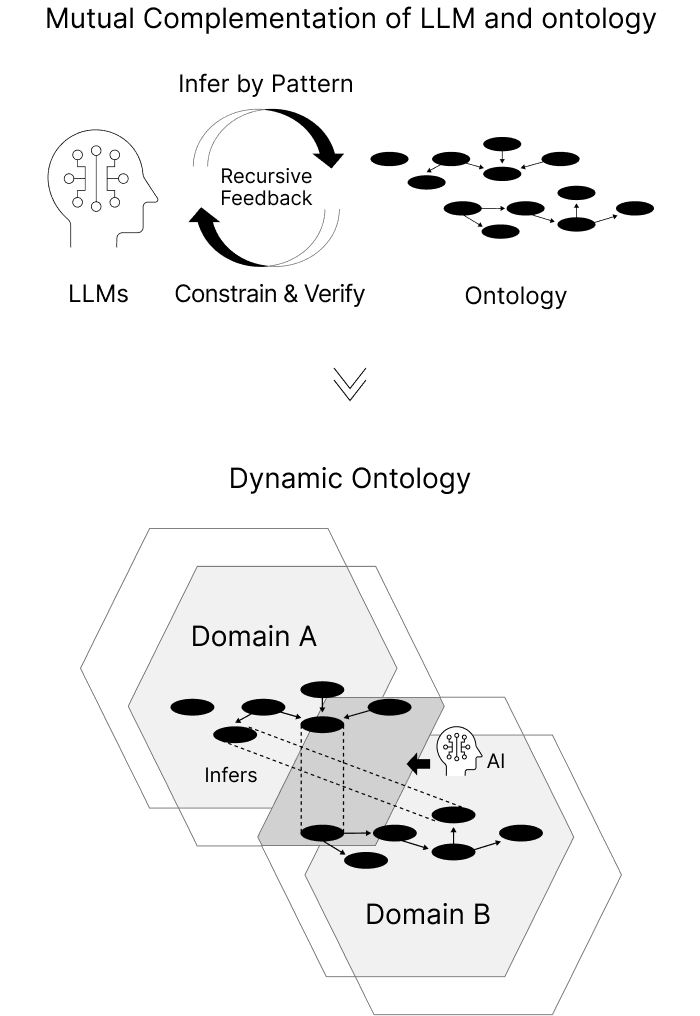
データの「構造」と「意味」を切り離して管理することで、システムを壊さずに意味の変化へ対応できます。
組織間で言葉の定義が違っても、AI(LLM)が意味のつながりを推測し、それをオントロジーによる論理的なルールで検証・補完します。このサイクルを回すことで、最初は不完全なデータでも共有を止めず、運用しながら「曖昧な推測」ではなく「確かな知識」として成立させることができます。
The Concept behind the Logo


DPQMの特徴的な構造をODSのVI(ビジュアル・アイデンティティ)に採用しています。
ロゴの使用に関しては、Open Data Spaces公式サイトおよび利用ガイドラインをよくお読みいただき、これらのガイドラインを遵守してください。
権利者による事前の許諾なく、Open Data Spacesのロゴ、アイコン、シンボル、またはデザインを使用することはできません。
FAQ
Open Data Spaces (ODS)に関する表記や推奨表現にはどのようなルールがありますか?
詳しくは、デザインガイドの「ODS公式ブランド表記と推奨表現に関するルール」を参照してください。また、次項のFAQに記載の非推奨事項も参照してください。
ODSの成果物(アーティファクト)を参照するときに「基づく」「準拠」「適合」「認証」という表現を使っても良いですか?
ODSの導入やシステム開発を検討しています。どの成果物(アーティファクト)から読んだらよいでしょうか?
ODSへの理解を深めて頂くために以下の目的に応じてをお読み頂くことを推奨いたします。
- ODSのソフトウェアやデータマネジメントサービス提供をご検討されている方向け
ODS 事業者向け参入ガイドブック(開発事業者向け) - ODSのサービスを利用または実装をご検討されている方向け
ODS 事業者向け参入ガイドブック(ユーザー事業者向け) - ソフトウェア開発をご検討されている技術者の方向け
ODS技術者向け導入ガイドブック - アーキテクチャの設計思想について知りたい方向け
Why Open Dataspaces: 設計思想とアーキテクチャパラダイム
ODSの実装を検討しています。SDKなどは提供されていますか?
ODS Protocols (ODP)を参照実装したオープンソースソフトウェア (OSS)及びSDKを公開しています。
詳細は以下をご参照ください。
- ODP参照実装OSS:ODS Middleware
- SDK:ODSソフトウェア開発キット